
À une époque où l'efficacité est essentielle, de nombreuses entreprises remettent en question le temps et les ressources consacrées aux audits de référencement techniques.
Cependant, la coupe des coins dans ce domaine critique peut entraîner des informations incomplètes et des opportunités manquées.
Plongeons pourquoi le référencement technique mérite un investissement ferme dans l'effort humain et dans le temps, en commençant par le défi souvent négligé du temps de framer.
Temps de rampe: l'entrave primaire
La réduction du temps de ressources humaines dans votre référencement ou du département de marketing numérique en réduisant le référencement technique peut être imprudente.
Pourquoi?
Le principal facteur derrière le temps pris pour les audits est le temps d'exploration.
Avec les architectures Web complexes d'aujourd'hui, cela est inévitable.
Les sites Web de commerce électronique, en particulier, ont rapidement élargi les empreintes de pas avec d'innombrables pages de produits et de blogs.
Chaque produit comprend souvent plusieurs images, augmentant le nombre d'adresses sur place de façon exponentielle.
Les employeurs et les clients demandent fréquemment:
«Pourquoi ces audits prennent-ils si longtemps? Vous ne pouvez pas vous concentrer uniquement sur les meilleurs problèmes et gagner du temps? »
La réponse est à la fois «oui» et «non».
Bien que se concentrer sur les problèmes supérieurs puisse réduire légèrement le temps consacré aux commentaires et à la visualisation des données, la plupart du temps pris dans les audits techniques de référencement est le temps de narration.
L'impact sur la précision globale de l'audit reste négligeable car la rampe elle-même – plutôt que l'analyse des données – domine la chronologie.
Bien que certains soutiennent que le temps d'exploration est le temps de la machine et ne devrait pas affecter l'effort humain, cela n'est que partiellement vrai.
Des plateformes comme Semrush ou Ahrefs peuvent rationaliser ramper si elles sont correctement configurées, surveillées et financées pour gérer toutes les propriétés Web en continu.
Cependant, l'exportation, le pivotage et l'analyse des données nécessitent toujours un effort manuel important.
Les experts techniques de référencement peuvent rarement s'appuyer sur des rapports générés par la plate-forme sans autre raffinement.
Par exemple, la plupart des robots de référencement ont du mal à identifier le contenu en double vrai.
Souvent, ce qui est signalé en double se révèle être des URL des paramètres, que Google ignore pour l'indexation.
De même, les implémentations de balises canoniques échouées peuvent tort apparaître comme du contenu en double.
L'utilisation d'outils tels que Screaming Frog ajoute une autre couche de complexité.
Bien que très rentable et puissant, il produit des feuilles de calcul brutes nécessitant une analyse manuelle. L'onglet des problèmes est rarement précis sans plus de filtrage de données.
En tant qu'outil côté client, crier la grenouille nécessite également que la machine de l'utilisateur reste active pendant les rampes.
Si les employés utilisent des machines personnelles, ils peuvent être réticents à les laisser courir pendant la nuit sans une compensation appropriée.
De plus, l'outil n'ajuste pas automatiquement les taux de nardine, nécessitant une supervision humaine pour éviter un comportement de type DDOS non intentionnel.
Alors que le temps de chapelure est principalement axé sur la machine, la surveillance et l'intervention humaines sont souvent nécessaires.
En supposant que la réduction du temps de rampe raccourcira considérablement les audits techniques de SEO peut conduire à des résultats inexacts et à des informations négligées.
Mutualité html tag
HTML TAG Mutualité, en particulier avec les étiquettes Hreflang, montre pourquoi la réduction du temps de chantier est déconseillée si vous voulez des informations techniques techniques précises.
Comme le SEO a évolué, les étiquettes HTML mutuellement dépendantes, comme les étiquettes Hreflang, sont devenues de plus en plus courantes.
Les balises Hreflang définissent les relations entre les pages dans différentes langues et doivent toujours être réciproques.
Si une page se lie à une autre avec une balise Hreflang, mais que l'URL de destination ne renvoie pas la même balise, la relation n'est pas valide et ignorée par Google.
Même les balises non mutuelles, telles que les balises canoniques, font souvent référence aux adresses externes qui doivent également être rampantes.
La rampe d'une seule section d'un site (par exemple, une variante de langue) vous laisse incapable de vérifier si les balises Hreflang pointent selon les besoins.
Cela peut entraîner des erreurs non défercées qui sont essentielles pour les performances du site mais restent non détectées en raison de données de rampe partielle.
De même, les étiquettes canoniques, bien qu'elles ne nécessitent pas de mutualité, peuvent également poser des défis.
Si une balise canonique pointe vers une page en dehors de votre échantillon de rampe, vous ne pouvez pas confirmer s'il fait référence à une adresse valide.
Voici un diagramme de la façon dont les balises canoniques et les balises Hreflang doivent interface:
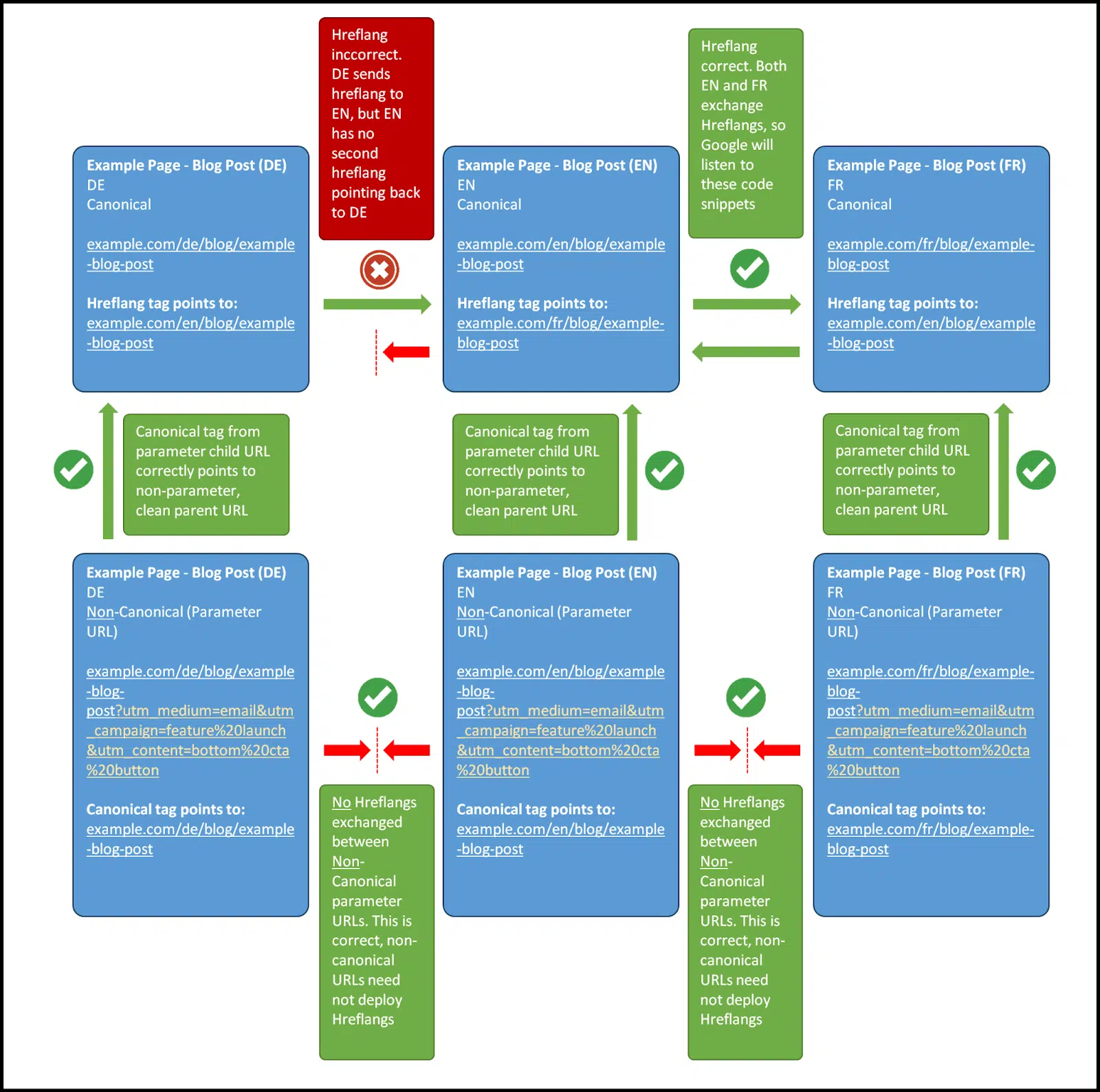
Ces problèmes illustrent à quel point les données d'exploration incomplètes peuvent entraver un audit technique de référencement approfondi.
Les données partielles vous obligent à compter sur des hypothèses plutôt que sur des preuves concrètes, ce qui rend imprudent de réduire le temps d'exploration pour accélérer les audits.
Liens et redirection
La production de données d'exécution précises a nécessité des efforts importants depuis les premiers jours du Web, bien avant que la mutualité de tag html ne devienne courant.
Les pages ont toujours lié à d'autres en utilisant le étiqueter.
Si votre échantillon de rampe comprend des liens pointant vers des adresses en dehors de celui-ci, vous ne pouvez pas vérifier si ces liens fonctionnent correctement sans ramper les pages de destination.
Certaines plates-formes rampantes de cloud abordent cela en vérifiant les codes d'état des pages externes ou redirigées sans analyser leur HTML complet.
Bien que cela puisse aider dans certains cas, il s'engage souvent à des problèmes plus profonds qui restent non examinés.
Les redirects présentent des défis similaires.
Si une page de votre échantillon de rampe pointe vers une destination à l'extérieur, vous ne pouvez pas analyser complètement la chaîne de redirection.
Cela peut entraîner des recommandations de rédirition inexactes, provoquant potentiellement des problèmes importants pour le site.
Soyez prudent lors de la réduction du temps de référencement technique
Rien ne substitut à investir le temps nécessaire dans le référencement technique.
Bien que les échantillons de rampe incomplets ou les rampes sans surveillance puissent sembler un moyen de réduire le temps de production d'audit, ils créent souvent plus de problèmes qu'ils ne résolvent.
Couper les coins peut entraîner des problèmes négligés, il est donc crucial de donner vos audits – et les experts qui les mènent – le temps dont ils ont besoin.
Cela ne tient même pas compte des chèques manuels que les professionnels du référencement effectuent en plus de ramper, de manipulation des données, de formatage et d'analyse.
Ces efforts combinés montrent clairement que le temps consacré au référencement technique est justifié.
Évitez l'élagage excessif ou les raccourcis dans cette discipline.
Si vous devez travailler avec des données d'exploration partielles, assurez-vous qu'au moins 70% de comprature – 50% au minimum absolu.
Rien de moins de risques compromettant la précision de votre audit.
Les auteurs contributifs sont invités à créer du contenu pour les terrains de moteurs de recherche et sont choisis pour leur expertise et leur contribution à la communauté de recherche. Nos contributeurs travaillent sous la surveillance du personnel éditorial et les contributions sont vérifiées pour la qualité et la pertinence pour nos lecteurs. Les opinions qu'ils expriment sont les leurs.