
La recherche est morte, la recherche en direct!
La recherche n'est pas ce qu'elle était.
Les moteurs de recherche ne correspondent plus simplement aux mots clés ou aux phrases dans les requêtes utilisateur avec des pages Web. Nous allons bien au-delà du monde de la recherche lexicale, qui est simplement basé sur le texte sans comprendre les connexions sémantiques entre non seulement des choses, mais aussi des représentations multimédias des choses / concepts.
Aujourd'hui, l'IA peut comprendre, contextualiser et générer des informations en réponse à l'intention de l'utilisateur en utilisant largement la prédiction probabiliste et la correspondance des modèles.
Cette transformation est dictée par la récupération générative des informations.
La récupération des informations génératrices est un changement fondamental dans la façon dont les systèmes font surface et présentent les informations.
De la récupération à la génération
Pendant des décennies, les moteurs de recherche ont répondu aux requêtes utilisateur en pointant des documents qui pourraient contenir la réponse.
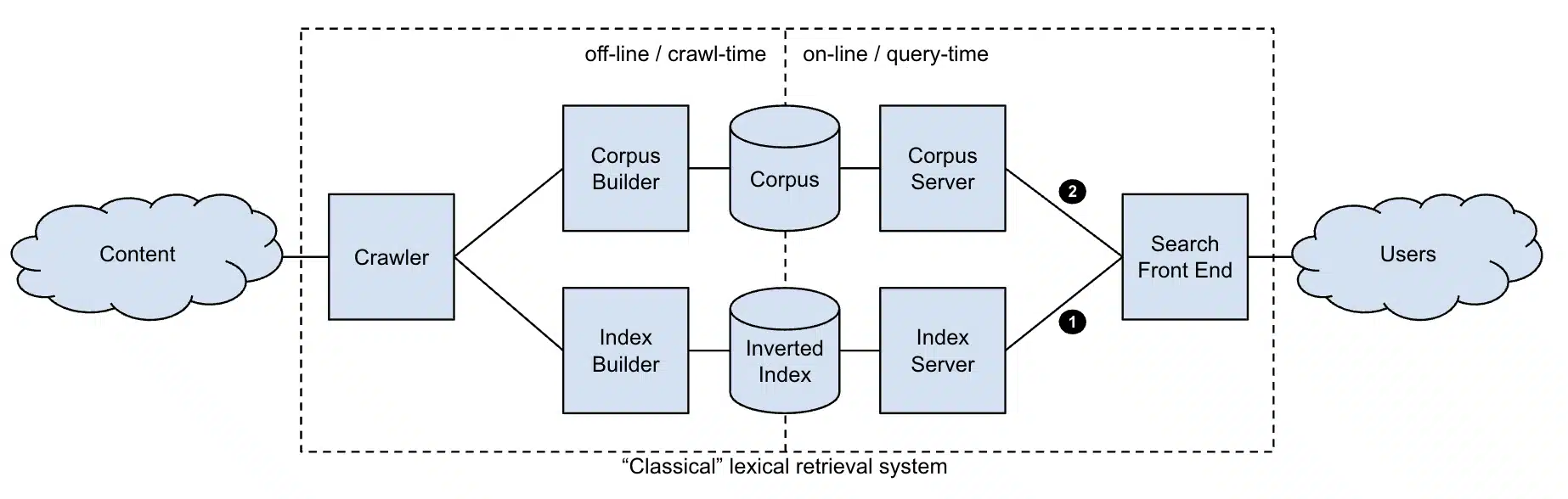
Mais ce modèle évolue. Nous sommes maintenant dans les premiers jours de la récupération générative de l'information.
Le système ne trouve pas seulement du contenu; Il génère des réponses en fonction de ce qu'il récupère de manière de plus en plus multimodale, rassemblant tout ce qu'une requête sous-spécifiée pourrait éventuellement représenter, synthétisant dans une seule vue.
Najork a décrit ce changement comme passant des systèmes traditionnels basés sur la récupération, qui renvoient une liste de documents classée, aux systèmes de génération (RAG) de la récupération.
Dans une configuration de chiffon, un modèle récupère les documents pertinents d'un corpus, puis les utilise comme connaissances et contexte de mise à la terre pour générer une réponse directe et en langue naturelle.
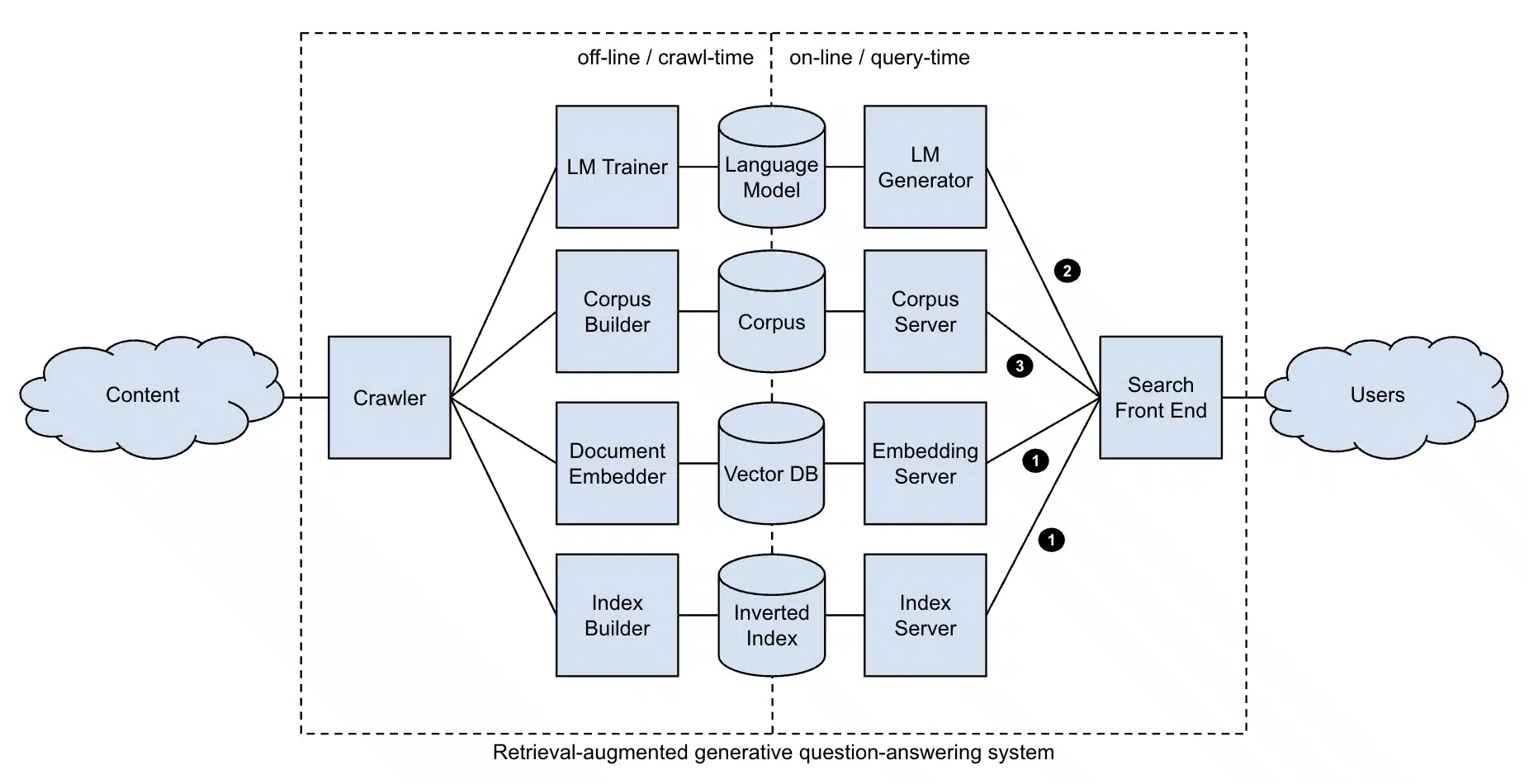
En termes simples, les chercheurs ne sont pas présentés avec une liste de liens vers des pages Web. Ils obtiennent des réponses directes synthétisées, souvent dans le ton et le style d'un assistant utile.
Cette nouvelle approche est alimentée par les LLM formées sur de grandes quantités de données et peut raisonner dans le contenu récupéré.
Ces systèmes sont imparfaits. Nous savons qu'ils hallucinent et se trompent des faits.
Nous pouvons voir par nous-mêmes les nombreuses façons dont les moteurs de recherche et autres sociétés technologiques utilisant l'IA et les modèles de grands langues, par exemple, pour résumer les titres et les résumés des nouvelles, ont du mal à contrôler la nature hallucinatoire des LLM et de l'IA générative.
Le problème?
L'IA générative est construite sur des modèles de probabilité plutôt que sur les faits.
Google recherche les raisons fondamentales pour lesquelles les titres et les résumés sont générés de manière incorrecte et a développé un cadre d'évaluation appelé Exhalateur. Un autre exemple est Bloomberg (Abonnement requis), qui a dû émettre plusieurs corrections aux résumés générés par l'IA et les LLM seulement la semaine dernière.
Quelles que soient les faiblesses de l'utilisation de LLMS dans la recherche (et elles ne sont pas sans controverse dans le monde de la récupération de l'information, comme Najork le fait dans sa présentation de Sigir en 2023) Générative AI / La récupération d'informations génératrices est hors de la porte et représente désormais un changement fondamental dans la façon dont les informations sont accessoires et livrées.
Cela a également des implications majeures pour le référencement. L'optimisation du contenu pour se classer dans «10 liens bleus» est différent de l'optimisation de l'inclusion dans un résumé généré par l'IA.
Défis de référence du trafic
Une grande question soulevée dans la présentation est ce qui arrive au trafic de référence lorsque les modèles de langue génèrent des réponses.
Nous avons vu cette question se dérouler sous la forme de poursuites, tels que Chegg poursuivent Google sur les aperçus de l'IA. Nous avons également entendu parler de nombreux sites Web de toutes tailles en voyant le trafic de recherche organique baisser depuis le lancement des aperçus de l'IA, en particulier pour les requêtes d'information.
Dans le modèle de recherche «classique», les utilisateurs ont cliqué sur des liens pour obtenir des informations, en conduisant le trafic vers les sites Web des marques, des créateurs et des entreprises. Cependant, avec des systèmes génératifs, les utilisateurs peuvent obtenir ce dont ils ont besoin directement à partir d'une réponse d'IA sans avoir besoin de visiter un site Web.
Cela a été une grande source de discorde. Si l'IA est formée sur le contenu «public» et utilise ce contenu pour générer des réponses, comment les sources d'origine obtiennent-elles un crédit ou, plus important encore, d'obtenir du trafic qu'ils peuvent monétiser?
Ce problème non résolu a des implications importantes pour quiconque s'appuie sur la visibilité de la recherche organique pour stimuler les résultats commerciaux. Et comme nous l'avons découvert récemment, Google a semblé visualiser en interne le trafic aux éditeurs un «mal nécessaire».
La présentation de Najork n'a pas offert de solution, mais cela semble faire allusion à un avenir sombre pour certains créateurs de contenu qui ne peuvent pas s'adapter à ce changement. Comme l'a dit Najork:
- La vue pessimiste: Les réponses directes réduisent les références aux fournisseurs de contenu, nuisant à leur capacité à monétiser.
- La vue optimiste: L'attribution dans les réponses directes conduira à des références de meilleure qualité qui, dans l'ensemble, sont plus précieuses.
- La vue réaliste: Attendez-vous à des modèles commerciaux diversifiés et à des sources de revenus.
Cependant, nous devons noter que la création de contenu est largement motivée par l'incitation du trafic axé sur les moteurs de recherche, et même un «mal nécessaire» est «nécessaire», il est donc plus difficile de s'adapter au nouveau paysage plutôt que d'abandonner le référencement.
Najork a également mentionné le terme important inventé uniquement en 2023 de «Delphic Cost» par Andre Broder, un ingénieur distingué chez Google, qui a également créé le célèbre Une taxonomie de la recherche sur le Web. L'argument autour des coûts Delphic est que le coût pour le chercheur est considérablement réduit en générant des réponses directement dans les résultats de recherche plutôt qu'en envoyant le chercheur à d'autres ressources, et cela devrait être un objectif clé des moteurs de recherche.
Comment cela sera-t-il réalisé et se jouera-t-il? Cela reste à voir.
Cependant, nous avons pu voir aussi récemment que l'événement de recherche de Google à New York à New York de nombreuses économies de coûts Delphic pour les chercheurs dans les présentations axées sur les futures.
Attendez-vous à des coûts Delphic (ou à une conversation similaire sur la réduction des frictions pour les chercheurs) et les éléments de recherche de la recherche d'utilisateurs pour influencer de plus en plus les communications entre Google et les SEO.
SEO contre GEO
Il y a eu un débat en cours et récent sur la sémantique parmi les influenceurs SEO et les experts sur LinkedIn et ailleurs sur la question de savoir si l'optimisation générative du moteur (GEO) est simplement un nouveau mot à la mode (et aussi, comment osons-nous renommer le référencement!).
J'ai vu beaucoup de cela récemment après l'article de Christina Adame, How to Intégrer GEO avec le référencement, publié ici sur Recherche Engine Land.
D'ACCORD. Personne ne renommage le référencement.
Le référencement n'est pas Geo.
Geo n'est pas un référencement. En fait, il y a Un document de recherche sur GEO.
Les moteurs génératifs (réponse) ne sont pas des moteurs de recherche. Comme Fred Laurent l'a mis en succinctement sur LinkedIn:
- «L'IA interprète, les moteurs de recherche classent»
C'est une différence clé à comprendre. Les citations / mentions dans la recherche générée par l'IA ne sont pas des classements traditionnels.
De plus, une voiture n'est pas un camion, mais les deux automobiles ont des moteurs qui peuvent vous aider à arriver là où vous voulez aller.
2023 peut être connu comme l'aube de la récupération des informations génératrices, mais cela ne signifie pas que la récupération de l'information a disparu. Il a simplement une autre facette. C'est aussi la façon dont le référencement.
Nous sommes dans une période de changements sans précédent.
La récupération des informations génératrices sous-tend la nouvelle réalité de la recherche, mais elle est toujours la recherche et la recherche d'informations, mais avec des nuances supplémentaires.
De la même manière, dans la recherche d'informations, il y a ceux qui se spécialisent dans les systèmes de recommandation, l'indexation, le classement, l'apprentissage du classement et le traitement du langage naturel (PNL) ou les zones de porte d'entrée autour de la façon dont les utilisateurs de moteurs de recherche interagissent avec les interfaces de recherche, ce changement dans le référencement crée également une autre zone nuancée où certains se concentreront et certains se généraliseront.
Les principes fondamentaux de base d'aider les utilisateurs à trouver les bonnes informations au bon moment restent les mêmes, quelle que soit la convention de dénomination.
Conclusion: le référencement évolue (encore).
Si vous vous accrochez à de vieux manuels de référencement, vous pouvez suivre le chemin du dinosaure dans un avenir très proche, alors que Google continue de s'éloigner de la recherche classique aux réponses d'IA.
Remarque: vous pouvez Voir le pont de Najork sur Google les diapositives. Astuce du chapeau à Dawn Anderson pour partager et réviser cet article pour précision.