
Amazon Web Services Inc. réinvente la manière dont les charges de travail analytiques gourmandes en données sont gérées par Amazon OpenSearch Service avec le lancement aujourd'hui d'un nouveau moteur d'analyse de journaux spécialement conçu.
Le géant du cloud computing affirme que le nouveau moteur est capable de réduire les coûts de stockage des données d'environ 70 % en moyenne tout en doublant le débit d'ingestion des données. De cette façon, les organisations peuvent effectuer des requêtes analytiques deux fois plus rapidement qu'auparavant, sans adapter la configuration matérielle sous-jacente.
Amazon OpenSearch Service est une version entièrement gérée de la plateforme open source OpenSearch, conçue pour gérer les charges de travail de recherche et d'analyse distribuées. Il est utilisé pour des tâches telles que la surveillance des applications en temps réel, l'analyse des journaux, la recherche sur le Web et la surveillance de la sécurité, ainsi que pour des applications d'observabilité à grande échelle.
Le service peut ingérer des flux massifs de données provenant de sources telles que l'infrastructure cloud, les applications et les périphériques réseau, avant d'être envoyés pour alimenter des tableaux de bord interactifs qui suivent l'état et les performances du système et identifient les problèmes opérationnels.
Avec cette mise à jour, AWS tente de surmonter un goulot d'étranglement critique pour les équipes DevOps des entreprises. Dans un article de blog rédigé par les architectes de solutions AWS Jagadish Kumar et Michael Suphagat, et le chef de produit Rohin Bhargava, la société a expliqué que la plupart des organisations voient leurs volumes d'analyse de journaux augmenter d'environ 30 à 40 % chaque année.
En effet, ils sont confrontés à un déluge croissant de données provenant d’applications d’intelligence artificielle. En conséquence, nombreux sont ceux qui doivent désormais choisir entre augmenter leur budget et ajouter une base de données analytique secondaire pour suivre le rythme, ou simplement supprimer une grande partie de leurs données de journal sans même les analyser.
Analyse accélérée des journaux
La solution d'AWS est un tout nouveau moteur d'analyse de journaux plus optimisé qui éloigne Amazon OpenSearch Service de son modèle de stockage unique et rigide. Le nouveau moteur est accessible en mode sélectionnable au sein du domaine Amazon OpenSearch Service et permet aux clients d'accélérer l'ingestion des données de journal tout en conservant leurs consoles, architectures de sécurité et configurations réseau existantes, ont indiqué les auteurs.
Le moteur fait cela car il introduit de nouvelles approches en matière de stockage et de traitement des données. Côté stockage, il peut désormais stocker les informations au format Apache Parquet en colonnes, plutôt que d'utiliser les index inversés traditionnels. Cela signifie que la disponibilité des données peut être optimisée à l'aide de techniques telles que l'encodage par dictionnaire et le regroupement numérique serré, éliminant ainsi la surcharge par document associée aux formats de stockage JavaScript Object Notation.
En ce qui concerne le traitement des données, le nouveau moteur introduit un routage intelligent des requêtes qui exploite l'outil open source Apache Calcite pour analyser les requêtes entrantes et les envoyer automatiquement au sous-moteur le plus efficace. Ainsi, des opérations analytiques plus approfondies sur les données en colonnes peuvent être gérées par Apache DataFusion, avec des requêtes standard envoyées à Apache Lucene.
Il prend également en charge l'exécution de requêtes unifiées, car les prédicats de recherche en texte intégral tels que MATCH et MATCH_PHRASE fonctionnent désormais de manière native dans les requêtes Structured Query Language et Piped Processing Language. Les équipes peuvent désormais filtrer des agrégations plus larges et explorer des recherches de points spécifiques avec une seule requête, ont expliqué les auteurs.
Kumar, Suphagat et Bhargava ont partagé une série de résultats de référence internes illustrant comment le nouveau moteur peut accélérer l'analyse des journaux à grande échelle. Lors de leurs tests, les ingénieurs ont analysé 24,4 milliards de documents et 9,5 téraoctets de données JSON brutes, atteignant un débit d'ingestion de 1,78 million de documents par seconde, soit environ deux fois plus que ce que l'Apache Lucene autonome peut gérer.
De plus, il l’a fait avec des besoins de calcul réduits. Le benchmark a également montré la capacité du moteur à traiter des requêtes analytiques filtrées dans le temps sur des milliards d'événements de journal en millisecondes, avec une amélioration quatre fois des performances globales en matière de prix.
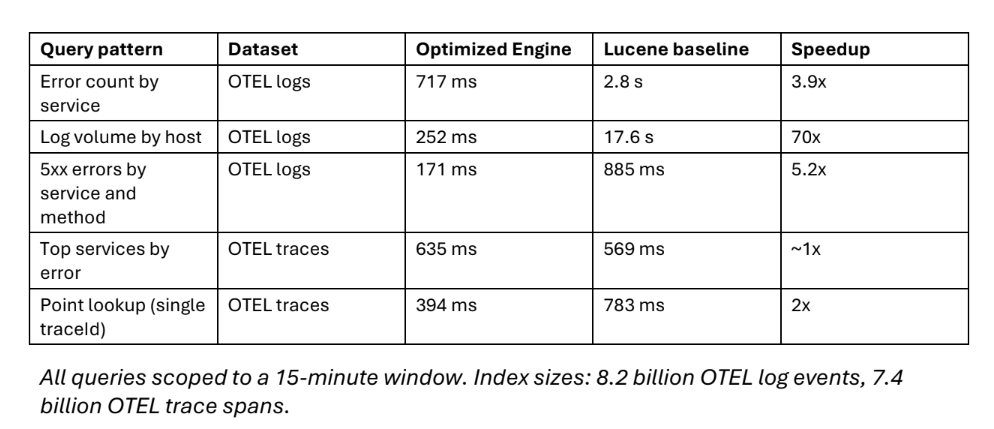
La meilleure nouvelle est peut-être que ces gains de performances sont désormais mis à la disposition de tous les clients AWS. Le moteur optimisé est accessible via Amazon OpenSearch Service dans toutes les régions AWS où les instances optimisées OpenSearch sont disponibles.
Les utilisateurs doivent sélectionner le nouveau moteur au moment de la création du domaine en choisissant « observabilité » comme cas d'utilisation principal depuis la console AWS. La tarification est basée sur les frais standard pour les instances et le stockage, sans prime.