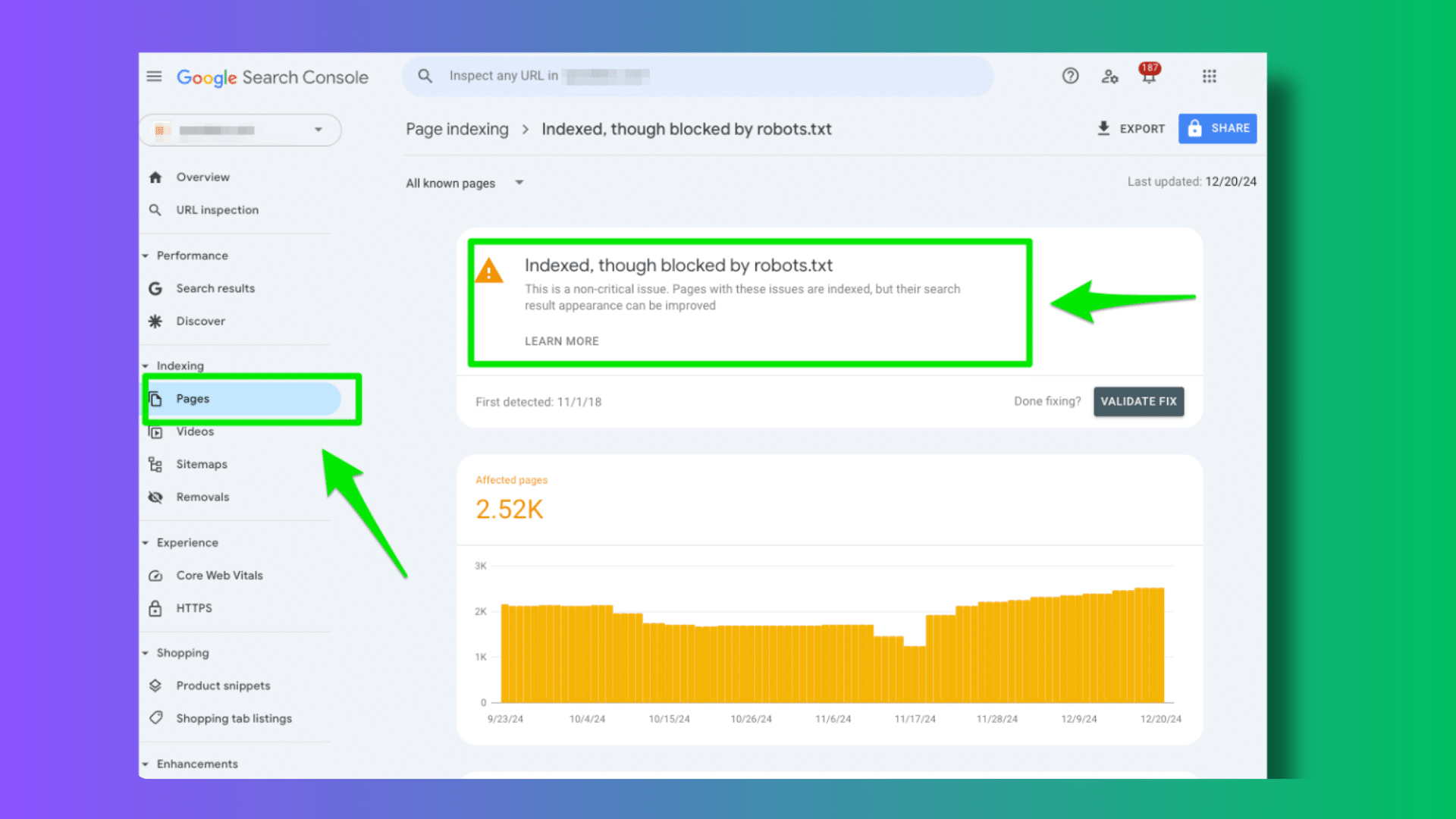
«Bloqué par robots.txt.»
«Indexé, bien que bloqué par Robots.txt.»
Ces deux réponses de la console de recherche Google ont divisé les professionnels du référencement, car les rapports d'erreur de la console de recherche Google (GSC) sont devenus une chose.
Il doit être réglé une fois pour toutes. Jeu sur.
Quelle est la différence entre «bloqué par robots.txt« vs »indexé, bien que bloqué par robots.txt»?
Il y a une différence majeure entre «bloqué par robots.txt» et «indexé, bien que bloqué par robots.txt».
L'indexation.
«Bloqué par robots.txt» signifie que vos URL n'apparaîtront pas dans Google Search.
« Indexé, bien que bloqué par robots.txt » signifie que vos URL sont indexées et apparaîtront dans Google Search même si vous avez tenté de bloquer les URL dans le fichier robots.txt.
Est mon URL vraiment Bloqué des moteurs de recherche si je le redoute dans le fichier robots.txt?
La réponse: Non.
Aucune URL n'est entièrement bloquée des moteurs de recherche d'indexation si vous interdire l'URL dans le fichier robots.txt.
Le scuttlebutt entre les professionnels du référencement et ces erreurs de console de recherche Google est que les moteurs de recherche n'ignorent pas complètement votre URL s'il est répertorié comme interdiction et bloqué dans le fichier robots.txt.
Dans ses documents d'aide, Google l'indique ne fait pas garantie La page ne sera pas indexée si elle est bloquée par robots.txt.
J'ai vu cela se produire sur les sites Web que je gère, ainsi que d'autres professionnels du référencement.
Lily Ray explique comment les pages bloquées par Robots.txt les fichiers sont éligibles à apparaître dans les aperçus de l'IA avec un extrait.
Ceci juste dans: les pages bloquées par Robots.txt sont éligibles pour apparaître dans les aperçus de l'IA. Avec un extrait. 🙀
Normalement, lorsque Google sert des pages bloquées dans ses résultats de recherche, il affiche «Aucune information disponible pour cette page» dans la description.
Mais avec AIO, apparemment Google montre un… pic.twitter.com/jrlswwgjh9
– Lily Ray 😏 (@lilyraynyc) 19 novembre 2024
Ray continue de montrer un Exemple de Goodreads. Une URL est actuellement bloquée par Robots.txt.
Quelque chose que je vois beaucoup dans AIO: il semble que lorsqu'un certain site est considéré comme une bonne ressource sur le sujet, ce site pourrait obtenir 3 à 5 liens au sein de l'AIO.
Dans cet exemple, Goodreads a 5 URL différentes citées dans la réponse (y compris une actuellement bloquée par Robots.txt 😛) pic.twitter.com/akilxvrk8v
– Lily Ray 😏 (@lilyraynyc) 19 novembre 2024
Patrick Stox a mis en évidence une URL bloquée par Robots.Txt peut être indexé S'il y a des liens pointant vers l'URL.
Les pages bloquées par robots.txt peuvent être indexées et servies sur Google si elles ont des liens qui les pointent.@danielwaisberg Pouvez-vous le rendre plus clair dans l'avertissement de test en direct dans GSC? pic.twitter.com/6aybweU8bf
– Patrick Stox (@patrickstox) 3 février 2023
Comment corriger «bloqué par robots.txt» dans la console de recherche Google?
Passez en revue manuellement toutes les pages signalées dans le « bloqué par Robots.txt'report
Tout d'abord, j'ai examiné manuellement toutes les pages signalées dans le rapport de la console de recherche Google «bloquée par robots.txt».
Pour accéder au rapport, allez à Console de recherche Google> Pages> et regardez sous la section Bloqué par robots.txt.
Ensuite, exportez les données vers Google Sheets, Excel ou CSV pour les filtrer.
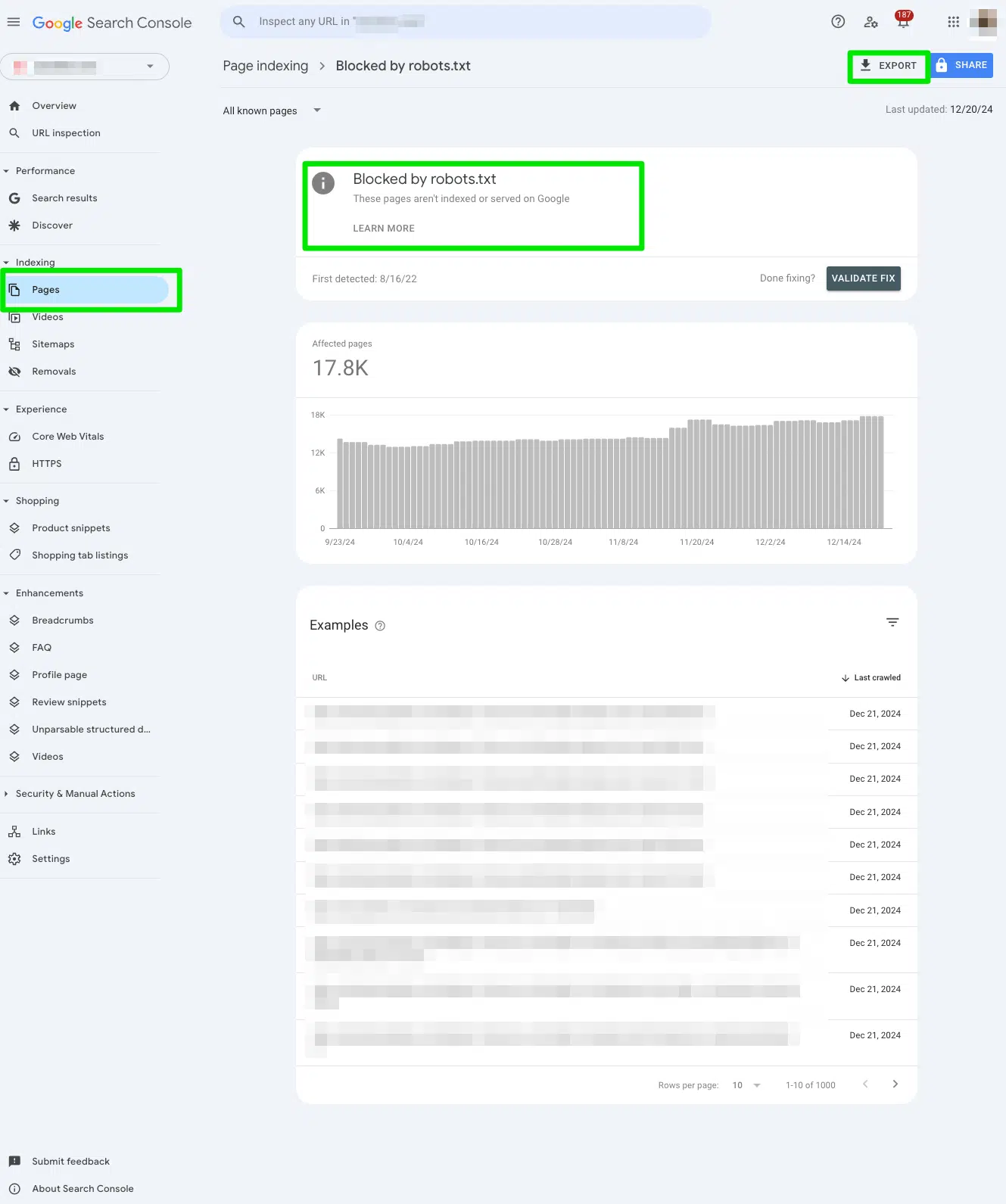
Déterminez si vous vouliez bloquer l'URL à partir des moteurs de recherche
Scannez votre document d'exportation pour des URL de haute priorité qui sont censées être vues par les moteurs de recherche.
Lorsque vous voyez l'erreur «bloquée par robots.txt», il indique à Google de ne pas ramper l'URL parce que vous avez implémenté une directive interdite dans le fichier robots.txt dans un but spécifique.
Il est tout à fait normal de bloquer une URL des moteurs de recherche.
Par exemple, vous pouvez bloquer les pages de remerciement des moteurs de recherche. Ou des pages de génération de leads destinées uniquement aux équipes de vente.
Votre objectif en tant que professionnel du référencement est de déterminer si les URL énumérées dans le rapport sont vraiment censées être bloquées et évitées par les moteurs de recherche.
Si vous avez intentionnellement ajouté l'interdiction dans le robots.txt, le rapport sera exact et aucune action ne sera nécessaire de votre côté.
Si vous avez ajouté l'interdiction dans les robots.txt sur accident, continuez à lire.
Retirez la directive de refus du robots.txt si vous l'avez ajouté accidentellement par erreur
Si vous avez accidentellement ajouté une directive d'interdiction à une URL par erreur, supprimez manuellement la directive interdite du fichier robots.txt.
Après avoir supprimé la directive de refus du fichier robots.txt, soumettez l'URL à Inspecter l'URL Bar en haut de la console de recherche Google.
Ensuite, cliquez Indexation des demandes.
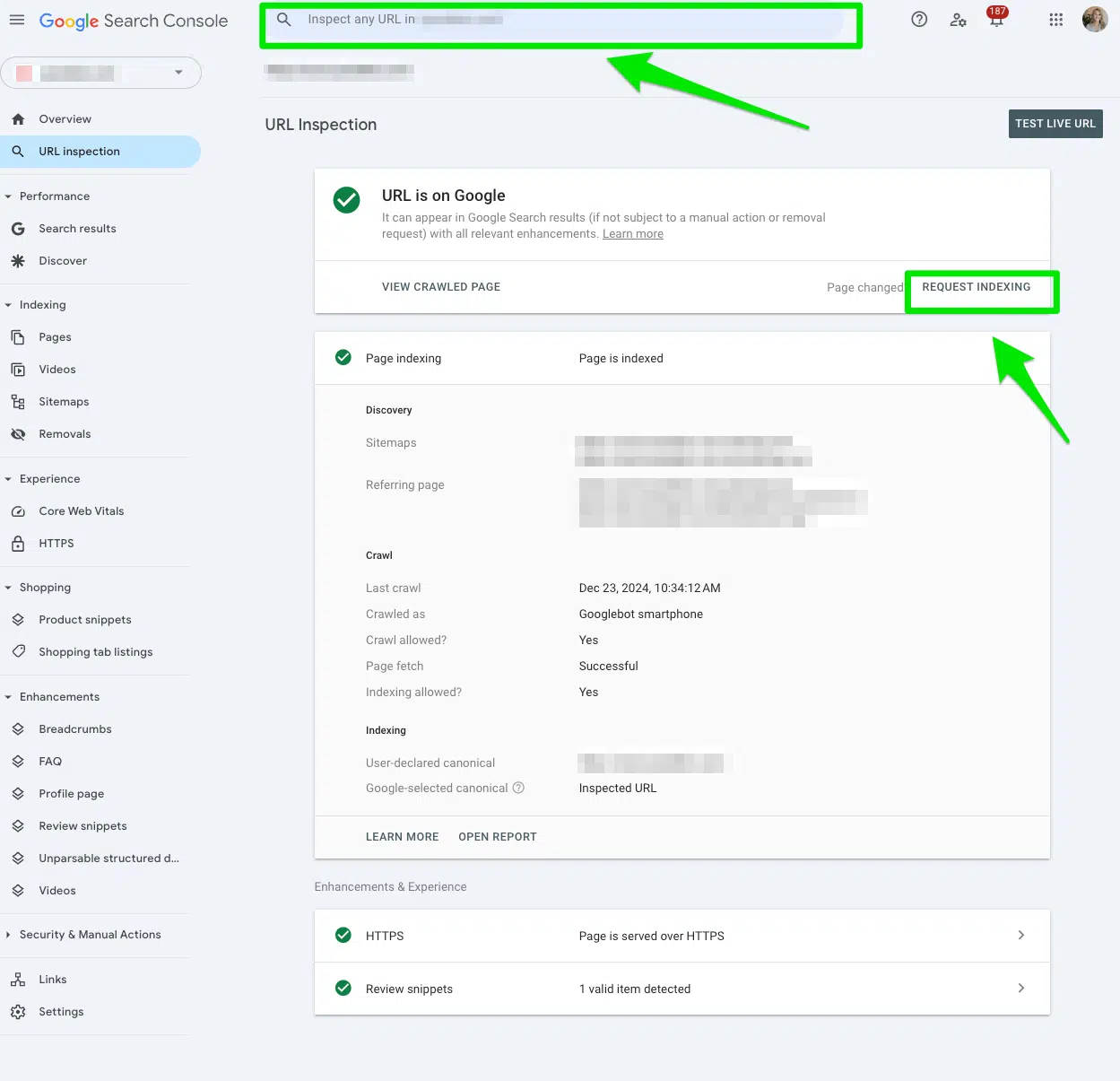
Si vous avez plusieurs URL sous un répertoire entier, commencez par la première URL du répertoire. Cela aura le plus grand impact.
L'objectif est de demander aux moteurs de recherche de recrandir ces pages et d'indexer les URL.
Demande de recrandant votre fichier robots.txt
Une autre façon de signaler à Google d'explorer vos pages refoulées accidentellement Demander un recrand Dans Google Search Console.
Dans Google Search Console, allez à Paramètres> robots.txt.
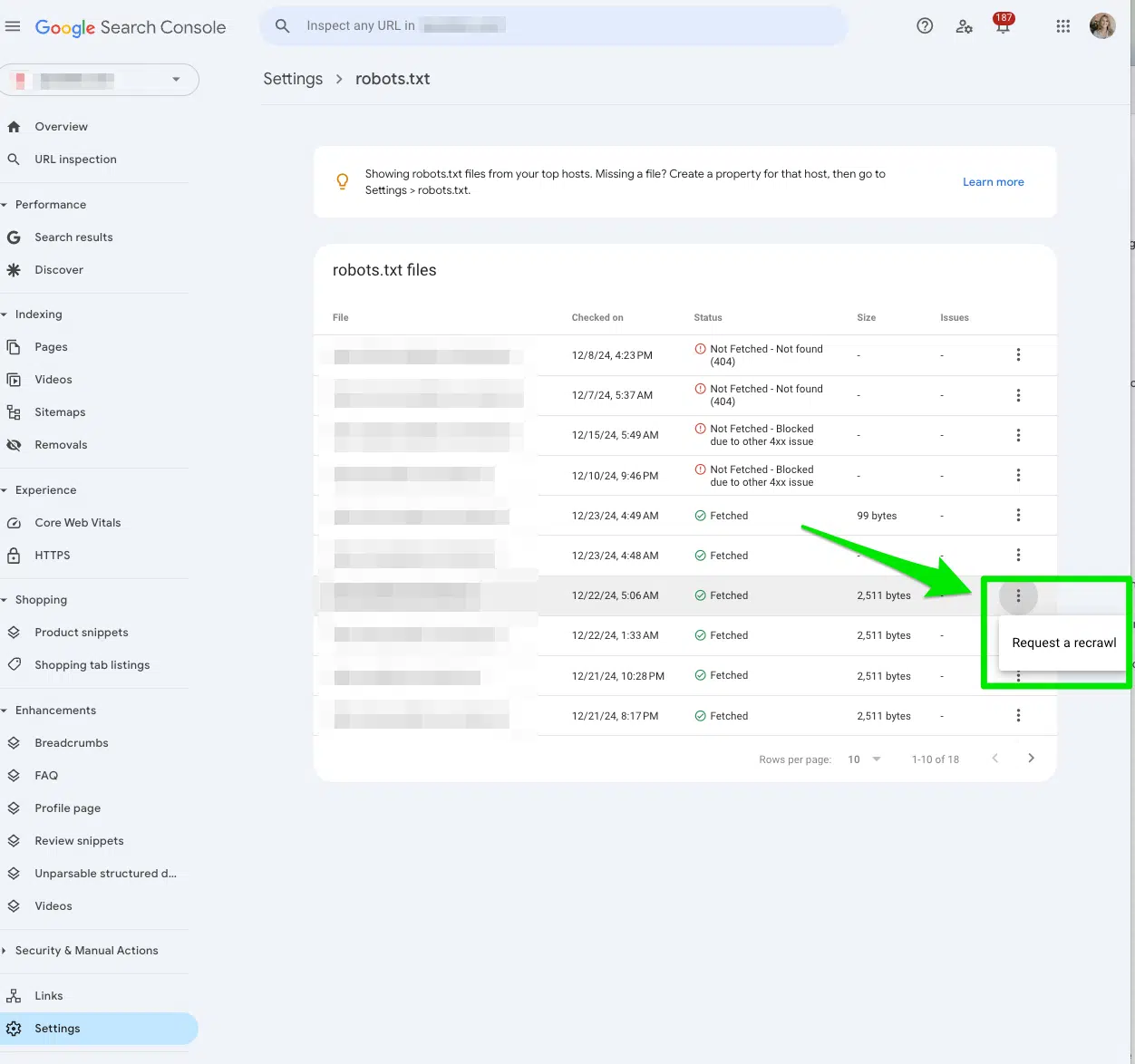
Ensuite, sélectionnez les trois points à côté du fichier robots.txt que vous souhaitez que Google recrame et sélectionnez Demandez un recraw.
Suivre les performances avant et après
Une fois que vous avez nettoyé votre fichier robots.txt, interdire les directives et soumis vos URL pour être recrutées, utilisez la machine Wayback pour vérifier lorsque votre fichier robots.txt a été mis à jour pour la dernière fois.
Cela peut vous donner une idée de l'impact potentiel de la directive d'interdiction sur une URL spécifique.
Ensuite, signalez les performances pendant au moins 90 jours après l'indexation de l'URL.
Comment résoudre 'indexé, bien que bloqué par robots.txt' dans la console de recherche Google?
Passez en revue manuellement toutes les pages signalées dans le rapport «indexé, bien que bloqué par robots.txt»
Encore une fois, sautez et passez en revue manuellement toutes les pages signalées dans le rapport «indexé sur la console de recherche Google« bien que bloquée par robots.txt ».
Pour accéder au rapport, accédez à Google Search Console> pages> et regardez sous la section Indexé, bien que bloqué par robots.txt.
Exportez les données pour les filtrer sur Google Sheets, Excel ou CSV.
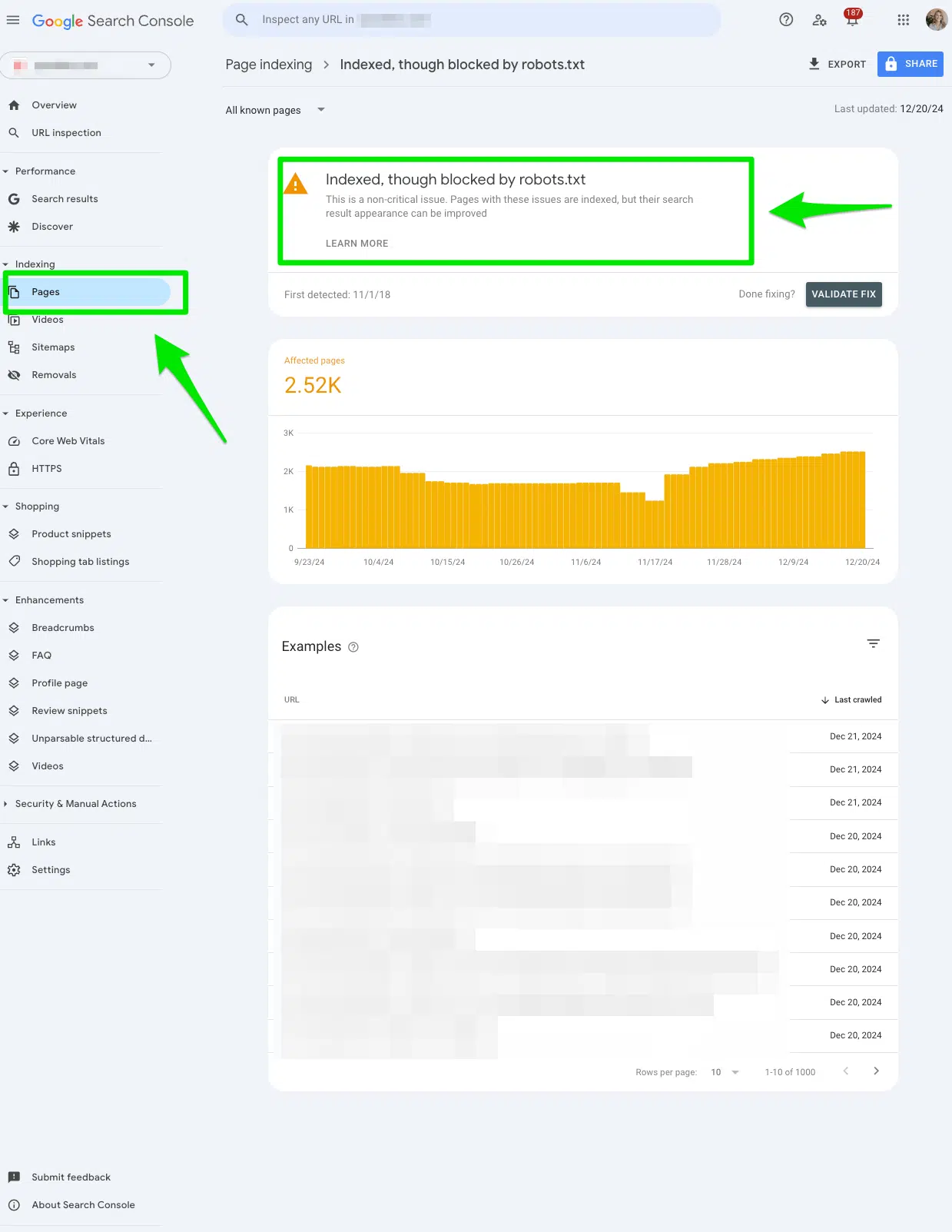
Déterminez si vous vouliez bloquer l'URL à partir des moteurs de recherche
Demandez-vous:
- Cette URL devrait-elle vraiment être indexée?
- Y a-t-il un contenu précieux pour les personnes qui recherchent sur les moteurs de recherche?
Si cette URL est censée être bloquée par les moteurs de recherche, aucune mesure ne doit être prise. Ce rapport est valide.
Si cette URL n'est pas censée être bloquée par les moteurs de recherche, continuez à lire.
Supprimez la directive de refus du robots.txt et demandez à recrraquer si vous voulez que la page soit indexée
Si vous avez ajouté à tort une directive d'interdiction à une URL par accident, supprimez manuellement la directive interdite du fichier robots.txt.
Après avoir supprimé la directive de refus du fichier robots.txt, soumettez l'URL à Inspecter l'URL Bar en haut de la console de recherche Google. Ensuite, cliquez Indexation des demandes.
Ensuite, dans la console de recherche Google, allez à Paramètres> Robots.txt> Demandez un recrand.
Vous voulez que Google recrandait ces pages pour indexer les URL et générer du trafic.
Ajoutez une balise NOINDEX si vous souhaitez que la page soit complètement supprimée des moteurs de recherche
Si vous ne voulez pas que la page soit indexée, envisagez d'ajouter une balise NOINDEX au lieu d'utiliser la directive Disallow dans Robots.txt.
Vous devez toujours supprimer la directive de désactivation de Robots.txt.
Si vous gardez les deux, le rapport d'erreur «indexé, bloqué par Robots.txt» dans Google Search Console continuera de croître, et vous ne résoudra jamais le problème.
Pourquoi pourrais-je ajouter une balise NOINDEX au lieu d'utiliser une directive de refus dans le robots.txt?
Si vous voulez une URL complètement supprimée des moteurs de recherche, vous devez inclure une balise NOINDEX. L'interdiction dans le fichier robots.txt ne garantit pas qu'une page ne sera pas indexée.
Les fichiers robots.txt ne sont pas utilisés pour contrôler l'index. Les fichiers robots.txt sont utilisés pour contrôler la rampe.
Dois-je inclure à la fois une balise NOINDEX et une directive interdite à la même URL?
Non. Si vous utilisez une balise NOINDEX sur une URL, n'oubliez pas la même URL dans les robots.txt.
Vous devez laisser les moteurs de recherche ramper sur la balise NOINDEX pour le détecter.
Si vous incluez la même URL dans la directive de refonte dans le fichier robots.txt, les moteurs de recherche auront du mal à ramper cette URL pour identifier que la balise NOINDEX existe.
La création d'une stratégie rampante claire pour votre site Web est le moyen d'éviter les erreurs robots.txt dans la console de recherche Google
Lorsque vous voyez l'un des rapports d'erreur Robots.txt dans Google Search Console Spike, vous pouvez être tenté de renseigner sur vos positions pour expliquer pourquoi vous avez choisi de bloquer les moteurs de recherche à partir d'une URL spécifique.
Je veux dire, une URL ne peut-elle pas être bloquée des moteurs de recherche?
Oui, une URL doit et peut être bloquée des moteurs de recherche pour une raison. Toutes les URL n'ont pas de contenu réfléchi et engageant destiné aux moteurs de recherche.
La panacée naturelle de ce rapport d'erreur dans Google Search Console est toujours de auditer vos pages et de déterminer si le contenu est destiné aux yeux des moteurs de recherche à voir.
Les auteurs contributifs sont invités à créer du contenu pour les terrains de moteur de recherche et sont choisis pour leur expertise et leur contribution à la communauté de recherche. Nos contributeurs travaillent sous la surveillance du personnel éditorial et les contributions sont vérifiées pour la qualité et la pertinence pour nos lecteurs. Les opinions qu'ils expriment sont les leurs.