
Nous recherchons constamment des moyens d’optimiser nos campagnes PPC et de maximiser leur impact.
Les tests sont essentiels à ce processus, mais les méthodes traditionnelles telles que les tests A/B, les évaluations d’incrémentalité et les expériences géographiques présentent souvent des limites importantes.
Les besoins importants en données, la planification poussée et la dépendance aux fonctionnalités de la plateforme publicitaire peuvent rendre difficile l'obtention d'informations claires et fiables.
Lorsque ces contraintes entrent en jeu, nous pouvons nous retrouver à prendre des décisions importantes basées sur des données incomplètes ou trompeuses, gaspillant ainsi notre budget ou manquant des opportunités d’évolution.
Cet article explore une technique de test puissante mais souvent négligée : les études d'impact causal. Découvrez comment elles fonctionnent, quand les utiliser et comment elles peuvent transformer votre approche de l'optimisation et de la prise de décision.
Que sont les études d’impact causal ?
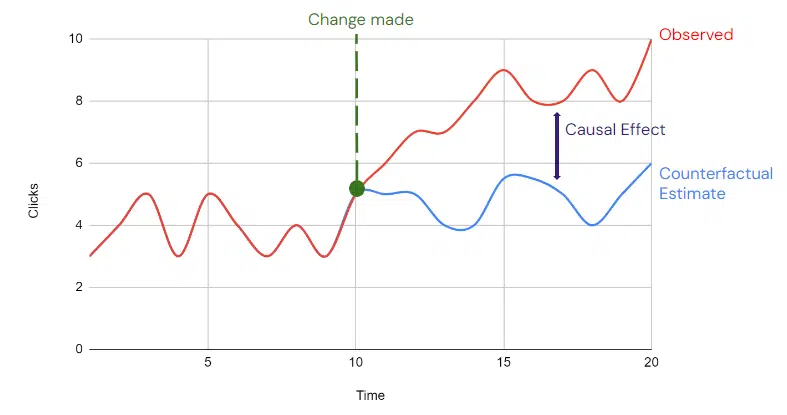
Les études d’impact causal mesurent avec précision les effets réels des changements dans vos campagnes en estimant un contrefactuel (c’est-à-dire, que se serait-il passé sans le changement mis en œuvre ?).
Il est essentiel de comprendre la différence entre corrélation et causalité.
Par exemple, si le nombre d'Aperol Spritz que je bois en été augmente parallèlement à mes plaintes concernant la chaleur, l'un n'est pas la cause de l'autre ; les deux sont influencés par le fait que le soleil est plus présent.
Les études d’impact causal vous aident à déterminer si un changement dans vos campagnes médiatiques payantes a directement provoqué un changement dans un KPI spécifique ou si ce changement se serait produit de toute façon.
L’étude prend un ensemble de données observées et estime ce scénario contrefactuel – en demandant essentiellement ce qui se serait passé sans le changement.
La différence entre ces données contrefactuelles et les données observées révèle l’effet causal de votre intervention.
Comment fonctionnent-ils ?
Dans un test A/B, deux groupes d'utilisateurs sont impliqués : l'un exposé à une condition de test et l'autre à des conditions de contrôle.
Vous pouvez observer les résultats pour les deux groupes : ce qui se passe avec la condition de test et ce qui se passe sans aucun changement.
Cependant, vous ne pouvez pas voir le résultat du groupe test si aucun changement n’avait été apporté, ni déterminer les performances du groupe témoin si la condition de test avait été appliquée.

Dans une étude d’impact causal, l’objectif est d’estimer le résultat pour le groupe test si aucun changement n’a été apporté (dans ce diagramme, groupe test 2) :

Pour établir cette estimation, vous devez trouver un autre ensemble de données de la même période qui est corrélé à votre KPI mais qui n'est pas affecté par le changement de campagne. Il peut s'agir de données d'une campagne similaire qui n'a pas été affectée par le test ou de données plus larges telles que des recherches de marque ou la demande globale de la catégorie.
Lorsque vous exécutez le modèle sur ces deux ensembles de données (vos données observées et l’ensemble de données corrélées), il examine d’abord la relation entre elles. Ensuite, il estime ce qui serait arrivé aux données observées s’il avait suivi cette relation au-delà du point d’implémentation.
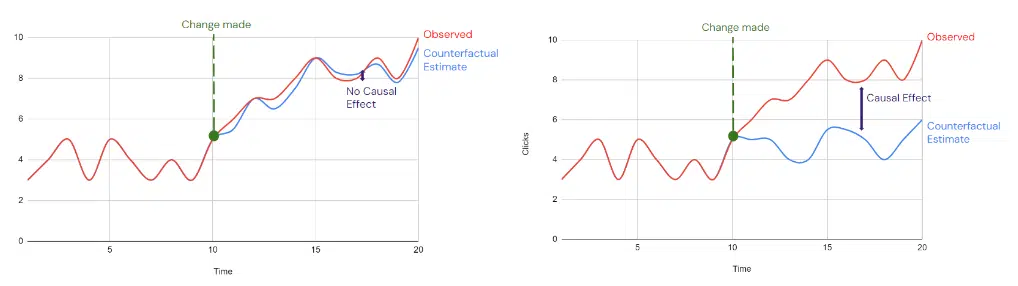
Si cette estimation correspond à vos données observées, cela indique que votre changement n'a eu aucun impact. Cependant, si l'estimation montre des résultats significativement différents, vous pouvez identifier un effet causal significatif.
L’étude exécute de nombreuses itérations du modèle pour générer une distribution de résultats estimés à partir desquels un intervalle de confiance peut être construit.
Pour valider vos résultats, vous pouvez toujours revenir à vos tests A/B.
Si vous effectuez un test A/B en utilisant les mêmes conditions de test, votre groupe témoin obtient-il la même tendance de données que votre estimation contrefactuelle ? Si tel est le cas, vous pouvez alors affirmer en toute confiance que votre modèle est précis.
Des informations complètes et des guides de mise en œuvre sur le package créé par Kay H. Brodersen et Alain Hauser sont disponibles sur GitHub. Je recommande également vivement de regarder Brodersen parler du sujet sur YouTube.
Quand utiliser les études d’impact causal
Dans quels cas est-il approprié de recourir à une étude d’impact causal ? Pour répondre à cette question, examinons les avantages et les inconvénients suivants.
Avantages
- Compréhension claire : Vous pouvez obtenir un aperçu clair de l’impact d’un changement spécifique.
- Flexibilité: La configuration du test est flexible et vous avez le contrôle sur les variables de confusion, telles que la saisonnalité, à condition de choisir le bon ensemble de données pour la comparaison.
- Analyse rétrospective : Ces tests peuvent être effectués rétrospectivement. Si un test A/B n'a pas été possible ou n'a pas été mis en œuvre, vous pouvez toujours analyser un changement passé pour déterminer s'il a eu un impact ou si d'autres facteurs ont influencé les résultats.
Inconvénients
- Expertise technique requise : La mise en œuvre du test nécessite un certain niveau de savoir-faire technique. Même si je bénéficie du soutien de mon équipe chez Google et de mon équipe de solutions de données, tout le monde n’a pas ce luxe.
- Besoin intensif en ressources : Si une hypothèse peut être correctement répondue à l’aide d’un test A/B, cette approche est généralement plus facile à mettre en œuvre et moins gourmande en ressources.
- Dépendance des données : La puissance du modèle dépend fortement de l'ensemble de données que vous utilisez pour l'entraîner. Si vous sélectionnez un ensemble de données qui n'est pas étroitement lié à votre KPI de test, votre modèle risque de ne pas être précis, ce qui peut entraîner des résultats non significatifs.
Si vous disposez des capacités techniques (ou de la volonté d’apprendre), d’un ensemble de données approprié pour la comparaison et que votre hypothèse ne peut pas être répondue par un test plus simple comme A/B, alors une étude d’impact causal est un outil précieux pour déterminer avec précision le véritable impact d’une intervention.
Par exemple, mon équipe effectue actuellement deux analyses pour un client : l'une dans laquelle nous avons désactivé son activité GDN et réaffecté ce budget à la génération de demande, et l'autre dans laquelle nous testons l'impact de l'ajout d'éléments dans une campagne Performance Max axée uniquement sur les flux. Les études d'impact causal nous aideront à déterminer si ces changements ont eu un impact significatif sur nos performances globales sur Google Ads.
Mon prochain test ?
Je vérifie si ma consommation d'Aperol Spritz est due au fait que le soleil brille davantage ou si cela a quelque chose à voir avec la longueur croissante de ma liste de choses à faire !
Mesurer l’efficacité réelle d’une campagne grâce à des études d’impact causal
Les études d’impact causal sont un outil puissant pour les spécialistes du marketing des médias payants qui cherchent à comprendre les véritables effets des changements de leur campagne.
En estimant avec précision les scénarios contrefactuels, ces études vous aident à discerner si les résultats observés résultent de vos actions ou d’autres facteurs.
Bien qu’ils nécessitent une certaine expertise technique et une sélection minutieuse des données, leur capacité à fournir des informations claires les rend inestimables pour optimiser les stratégies marketing.
L’adoption d’études d’impact causal peut conduire à des décisions plus éclairées et, en fin de compte, améliorer l’efficacité de vos campagnes.
Les auteurs contributeurs sont invités à créer du contenu pour Search Engine Land et sont choisis pour leur expertise et leur contribution à la communauté de recherche. Nos contributeurs travaillent sous la supervision de la rédaction et leurs contributions sont vérifiées pour leur qualité et leur pertinence pour nos lecteurs. Les opinions qu'ils expriment sont les leurs.