Vous êtes-vous déjà demandé pourquoi certains de vos produits de commerce électronique ou vos articles de blog n'apparaissent jamais sur Google?
La façon dont votre site gère la pagination pourrait être la raison.
Cet article explore les complexités de la pagination – ce qu'elle est, si votre site en a besoin pour le référencement, et comment il affecte la recherche en 2025.
La pagination est le cadre de codage et technique sur les pages Web qui permet de diviser le contenu sur plusieurs pages tout en restant thématiquement connecté à la page parent d'origine.
Lorsqu'une seule page contient trop de contenu pour charger efficacement, la pagination aide en la divisant en sections plus petites.
Cela améliore l'expérience utilisateur et débrouille le client (c'est-à-dire le navigateur Web) de charger trop d'informations – dont une grande partie peut même ne pas être examinée par l'utilisateur.
Listes de produits
Un exemple courant de pagination est de naviguer dans plusieurs pages de résultats de produits dans une seule alimentation ou une catégorie de produit.
Regardons les jours Virgin Experience, un site qui vend des expériences douées similaires aux jours de lettres rouges.
Prenez leur page Expériences de la fête des mères:
https://www.virginexperiencedays.co.uk/mothers-day-gifts
Faites défiler jusqu'à la section «toutes les expériences des expériences de cadeaux et les expériences des cadeaux», et vous verrez le choix de 1 635 expériences stupéfiantes.
C'est beaucoup.
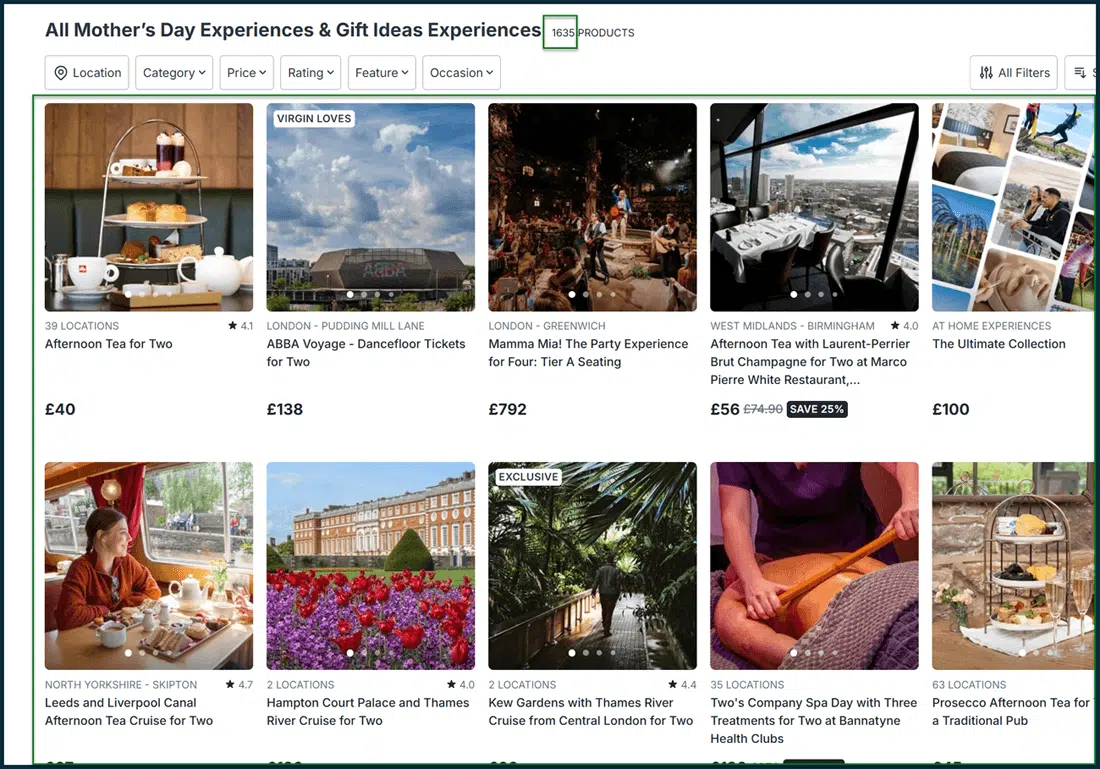
De toute évidence, les répertorier tous sur une seule page ne serait pas pratique.
Cela entraînerait un défilement vertical excessif et pourrait ralentir les temps de chargement de la page.
Plus bas sur la page, vous trouverez des liens de pagination:
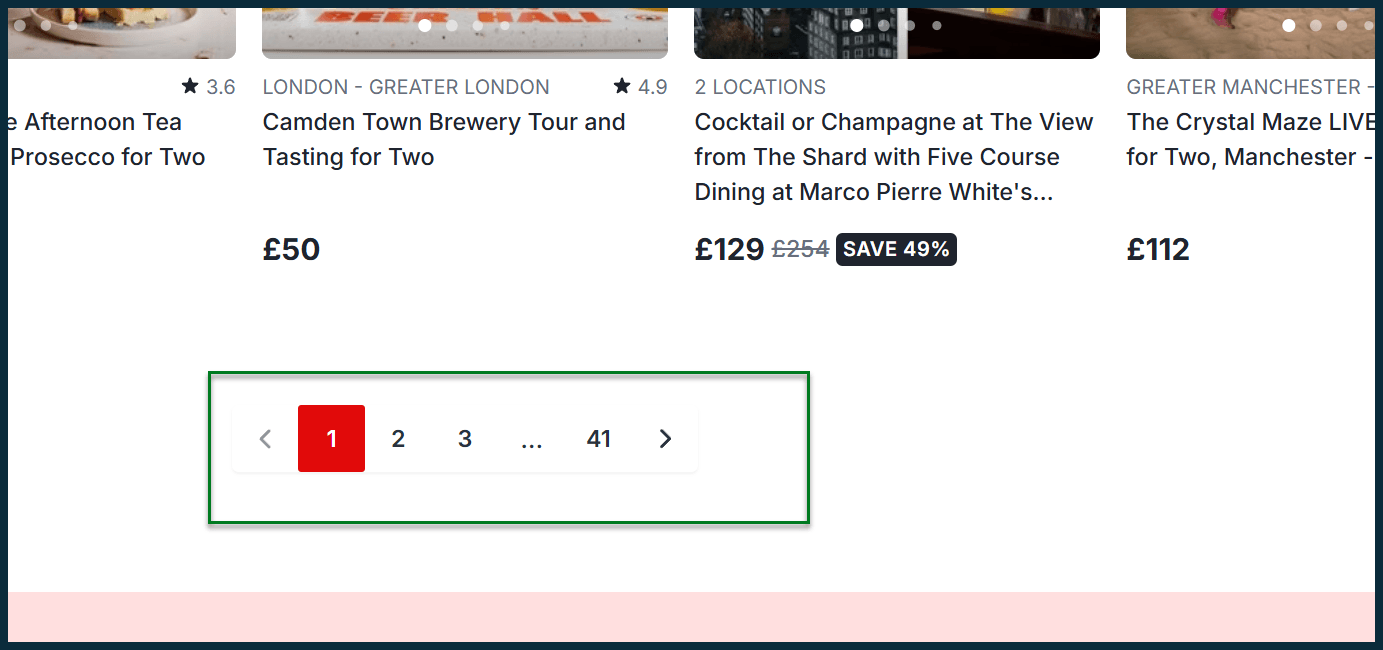
Cliquer sur un lien de pagination déplace les utilisateurs pour séparer les pages de liste de produits, telles que la page 2:
https://www.virginexperiencedays.co.uk/mothers-day-gifts?page=2
Dans l'URL, ?page=2 apparaît comme une extension de paramètre, une syntaxe de pagination commune.
Les variations incluent ?p=2 ou /page/2/mais l'objectif reste le même – permettant aux utilisateurs de parcourir des pages supplémentaires d'annonces.
Même les grands détaillants comme Amazon utilisent des structures de pagination similaires.
La pagination aide également les moteurs de recherche à découvrir des produits profondément imbriqués.
Si un site est si grand que tous ses produits ne peuvent pas être répertoriés dans un seul plan du site XML, les liens de pagination offrent aux robots un moyen supplémentaire d'y accéder.
Même lorsque des sitemaps XML sont en place, la liaison interne reste importante pour le référencement.
Bien que les liens de pagination ne soient pas le signal de classement le plus fort, ils jouent un rôle fondamental dans la conclusion du contenu.
Flux de blog et d'actualités
La pagination ne se limite pas aux listes de produits, elle est également largement utilisée dans les flux de blog et d'actualités.
Prenez l'archive de l'article SEO du moteur de recherche Land:
https://searchengineland.com/library/seo
Dans cette page, vous pouvez accéder à un flux de tous les messages liés au référencement sur les terrains du moteur de recherche.
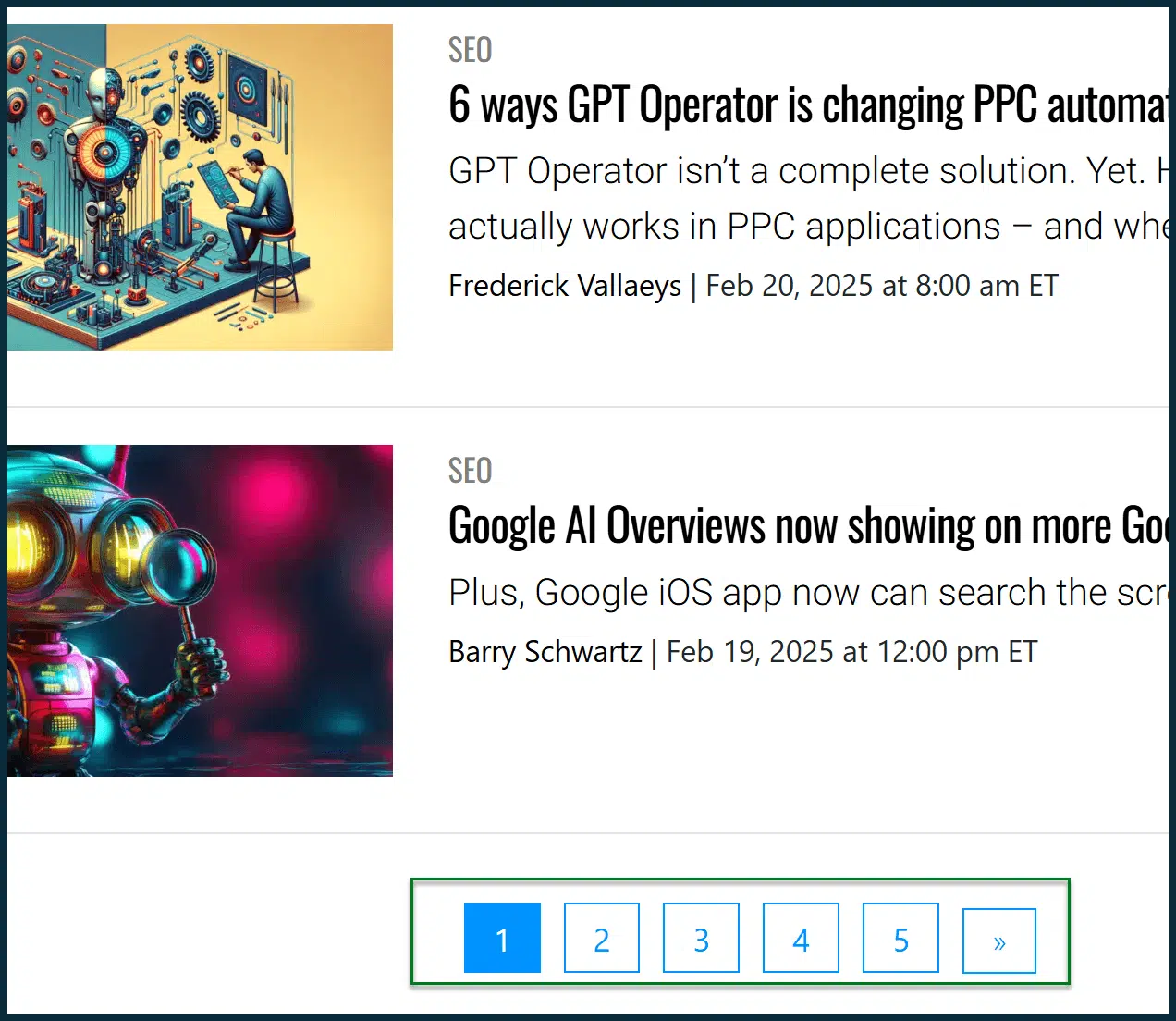
En faisant défiler vers le bas, vous trouverez des liens de pagination.
Cliquez sur «2» vous amène au prochain ensemble d'articles SEO:
https://searchengineland.com/library/seo/page/2
La pagination peut également exister dans des éléments de contenu individuels plutôt qu'à un niveau d'alimentation.
Par exemple, certains sites de nouvelles paginent des sections de commentaires lorsqu'un seul article reçoit des milliers de commentaires.
De même, les fils de forum avec des discussions étendues utilisent souvent une pagination pour rompre les réponses sur plusieurs pages.
Considérez ce message de WPBeginner:
https://www.wpbeginner.com/beginners-guide/how-to-choose-the-best-blogging-platform/
Faites défiler vers le bas et vous verrez que même la section de commentaires utilise une pagination pour organiser les réponses des utilisateurs.
La pagination joue un rôle crucial dans le référencement pour plusieurs raisons:
Indexage
Sans pagination, des robots de recherche peuvent avoir du mal à trouver du contenu profondément imbriqué tel que les articles de blog, les articles de presse, les produits et les commentaires.
Efficacité
La pagination augmente le nombre d'URL sur un site, ce qui peut sembler contre-productif à ramper efficace.
Cependant, la plupart des moteurs de recherche reconnaissent les structures de pagination communes – même sans balisage riche.
Cette compréhension leur permet de hiérarchiser le contenu plus précieux tout en ignorant les pages paginées moins importantes.
Lien interne
La pagination contribue également à la liaison interne.
Bien que les liens de pagination ne portent pas d'autorité de liens importants, ils fournissent une structure.
Google a tendance à accorder moins d'attention aux pages orphelines – celles sans liens entrants – donc la pagination peut aider à garantir que le contenu reste connecté.
Gérer la duplication de contenu
Si les URL ne sont pas correctement structurées, les moteurs de recherche peuvent les identifier par erreur comme du contenu en double.
La pagination n'est pas un signal de consolidation de contenu aussi fort que les redirectes ou les étiquettes canoniques.
Pourtant, lorsqu'il est mis en œuvre correctement, il aide les moteurs de recherche à différencier les pages paginées et les vrais doublons.
La dépréciation de Google de rel = prev / suivant
Google a précédemment pris en charge rel=prev/next pour déclarer le contenu paginé.
Cependant, en mars 2019, il a été révélé que Google n'avait pas utilisé ce balisage depuis un certain temps.
En conséquence, ces balises ne sont plus nécessaires dans le code d'un site Web.
Google probablement utilisé rel=prev/next pour étudier les structures de pagination communes.
Au fil du temps, ces informations ont été intégrées dans ses algorithmes de base, ce qui rend le balisage redondant.
Certains SEO pensent que ces étiquettes peuvent encore aider à ramper, mais il y a peu de preuves à l'appui.
Si votre site n'utilise pas ce balisage, il n'est pas nécessaire de s'inquiéter. Google peut toujours reconnaître les URL paginées.
Si votre site l'utilise, il n'y a pas non plus de besoin urgent de le supprimer, car il n'aura pas d'impact négatif sur votre référencement.
D'autres méthodes pour parcourir de grandes quantités de contenu ont émergé au cours des deux dernières décennies.
Les boutons «Voir plus» ou «Chargez plus» apparaissent souvent sous des flux de commentaires, tandis que les flux de défilement infini ou de chargement paresseux sont courants pour les publications et les produits.
Certains soutiennent que ces fonctionnalités sont plus conviviales.
Pionnier à l'origine par les réseaux sociaux tels que Twitter (maintenant X), cette forme de navigation a contribué à stimuler les interactions sociales.
Certains sites Web l'ont adopté, mais pourquoi n'est-ce pas plus répandu?
Du point de vue du référencement, le problème est que les robots de recherche de moteurs interagissent avec les pages Web de manière limitée.
Bien que les navigateurs sans tête peuvent parfois exécuter du contenu basé sur JavaScript lors d'une charge de page, les robots de recherche ne «font pas défiler» pour déclencher un nouveau contenu.
Un bot de moteur de recherche ne fait certainement pas défiler indéfiniment pour tout charger.
En conséquence, les sites Web reposent uniquement sur des articles, des produits et des commentaires de chargement de chargement infini ou des risques paresseux au fil du temps.
Pour les grandes marques d'information avec une forte autorité de référencement et de vastes planches XML, ce n'est peut-être pas une préoccupation.
Le compromis entre le référencement et l'expérience utilisateur peut être acceptable.
Mais pour la plupart des sites Web, la mise en œuvre de ces technologies est probablement une mauvaise idée.
Les robots de recherche peuvent ne pas passer du temps à faire défiler les flux de contenu, mais ils cliqueront sur les hyperliens – y compris les liens de pagination.
Même si votre site n'utilise pas de plugins à défilement infini, JavaScript peut toujours interférer avec la pagination.
Depuis juillet 2024Google a au moins tenté de rendre JavaScript pour toutes les pages visitées.
Cependant, les détails à ce sujet restent vagues.
- Google rend-il toutes les pages, y compris JavaScript, au moment de la rampe?
- Ou l'exécution est-elle différée à une file d'attente de traitement séparée?
- Comment cela affecte-t-il les algorithmes de classement de Google?
- Google fait-il des déterminations initiales avant d'exécuter JavaScript des semaines plus tard?
Il n'y a pas de réponses définitives à ces questions.
Ce que nous savons, c'est que «le rendu dynamique est en baisse», selon le chapitre Web Almanac SEO 2024.
Si les efforts de Google pour exécuter JavaScript pour toutes les pages rampantes progressent bien – ce qui semble peu probable étant donné les inconvénients potentiels de l'efficacité – pourquoi tant de sites reviennent-ils à un état non dynamique?
Cela ne signifie pas que l'utilisation de JavaScript disparaît.
Au lieu de cela, plus de sites peuvent passer à un rendu côté serveur ou côté bord.
Si votre site utilise la pagination traditionnelle mais que JavaScript interfère avec les liens de pagination, cela peut toujours entraîner des problèmes rampants.
Par exemple, votre site peut utiliser des liens de pagination traditionnels, mais le contenu principal de votre page est chargé de paresseux.
À son tour, les liens de pagination n'apparaissent que lorsqu'un utilisateur (ou BOT) fait défiler la page.
Les professionnels du référencement recommandent souvent d'utiliser des étiquettes canoniques pour pointer des URL paginées à leurs pages parents, les marquant comme non canoniques.
Cette pratique était particulièrement courante avant l'introduction de Google rel=prev/next.
Depuis que Google a déprécié rel=prev/nextde nombreux SEO restent incertains sur la meilleure façon de gérer les URL de pagination.
Évitez de bloquer le contenu paginé via des robots.txt ou avec des balises canoniques.
Cela empêche Google de ramper ou d'indexer ces pages.
Dans le cas des articles d'actualités, certains échanges de commentaires pourraient être considérés comme précieux par Google, en connectant potentiellement une version paginée d'un article avec des mots clés qui n'en seraient pas autrement associés.
Cela peut générer du trafic gratuit – quelque chose qui mérite d'être conservé en 2025.
De même, la restriction de la rampe et de l'indexation des aliments paginés pourrait laisser certains produits efficacement à l'orphelin.
Dans le référencement, il y a une tendance à chasser la perfection et à viser un contrôle complet de la rampe.
Mais être trop agressif ici peut faire plus de mal que de bien, alors marchez avec soin.
Il y a des cas où il est logique de dés-canonicaliser ou de limiter le rampage des URL paginées.
Avant de faire cette étape, assurez-vous d'avoir des données montrant que les problèmes d'efficacité de rampe l'emportent sur les gains de trafic libre potentiels.
Si vous n'avez pas ces données, ne bloquez pas les URL. Simple!
Les auteurs contributifs sont invités à créer du contenu pour les terrains de moteur de recherche et sont choisis pour leur expertise et leur contribution à la communauté de recherche. Nos contributeurs travaillent sous la surveillance du personnel éditorial et les contributions sont vérifiées pour la qualité et la pertinence pour nos lecteurs. Les opinions qu'ils expriment sont les leurs.