
En tant que référenceurs, nous rencontrons souvent les choses les plus étranges classées dans les SERP :
Pourquoi Reddit est-il classé pour un mot-clé purement commercial qui renvoie généralement des URL de commerce électronique ?
Pourquoi The Verge est-il bien classé avec un article spammé, sarcastique et apparemment généré par l'IA, rempli de mots-clés tels que « meilleure imprimante 2024 » ?
L'article de The Verge marchait bien lors de sa première publication en avril 2024, mais a commencé à baisser de classement à la mi-mai. C'est toujours un classement élevé qui me laisse perplexe 🤷, mais au moins maintenant nous savons qu'il ne mérite pas une place dans le top 10 (ou le sommes-nous ?).
Les gens ont souvent des idées dépassées sur la façon dont Google classe les pages. Nous nous en tenons aux anciennes méthodes parce qu'elles nous sont familières, même si nous ne comprenons pas entièrement comment fonctionne le système actuel de Google.
Par exemple, nous insistons toujours sur les mots-clés comme facteur clé du classement. Mais sont-ils vraiment aussi importants que nous le pensons ? Et si ce n'est pas le cas, sur quoi devrions-nous plutôt nous concentrer ?
« Meilleure imprimante 2024 » : quel est le classement ?
Les types de contenu des 10 premiers résultats pour « meilleure imprimante 2024 » sont intéressants. Il y a trois URL UGC dans le top 10 :
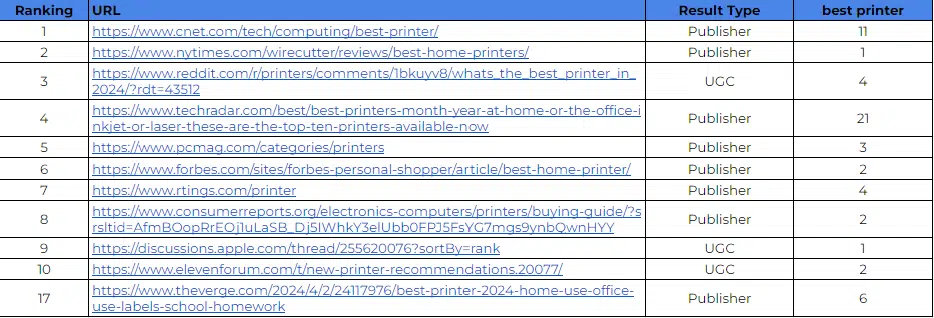
Ensuite, l'autre type de résultat est celui des éditeurs classés avec des listes. Aucune boutique de commerce électronique n'apparaît dans le résultat, y compris les grands noms comme Amazon.
Pourquoi ce classement sur Google ?
Si vous êtes surpris que Google classe une URL qui, selon vous, ne devrait pas figurer sur la page 1, c'est peut-être parce que votre compréhension du classement est obsolète.
Voici quelques raisons, ou appelez-les signaux de classement si vous préférez, qui me semblent importantes aujourd'hui.
1. Autorité
Google privilégie les marques établies. Que cela nous plaise ou non, les marques connues ont plus de chances d'être mieux classées dans les résultats de recherche que les sites Web moins connus.
Voici les éléments qui sont souvent associés aux sites Web faisant autorité et de bonne marque dans les SERP :
- Les marques sont connues des utilisateurs, car elles sont plus susceptibles de cliquer et de faire confiance à leurs URL lorsqu'ils les voient dans les SERP. Une meilleure image de marque signifie simplement un meilleur CTR.
- Naturellement cités/liés à des sites Web à partir d'autres sites Web dans des contextes pertinents. Oui, les backlinks comptent toujours.
- Sites Web avec présence sur les réseaux sociaux.
- Sites Web qui ont été reconnus comme entités dans les SERP et qui disposent de leur propre panneau de connaissances.
- Sites Web sécurisés avec un objectif clair et des politiques éditoriales transparentes, des politiques d'expédition et de retour, de bonnes pages juridiques et de confidentialité et des informations sur leur équipe et sur les personnes qui ont rédigé/révisé le contenu. N'oubliez pas que l'importance de l'EEAT varie en fonction du créneau, mais l'application des meilleures pratiques est toujours une bonne chose.
Emporter
La marque est importante et le référencement n'est plus un canal marketing autonome. En tant que référenceurs, nous devons travailler avec d'autres fonctions marketing pour trouver des opportunités de construire une marque forte dans les SERP.
2. Comportement de l'utilisateur
Certains membres de la communauté SEO résistent à l'envie de se concentrer sur le comportement des utilisateurs car il n'existe pas de tactiques claires pour l'améliorer.
Il semble souvent plus facile de s’en tenir à des tactiques familières, même si elles ne fonctionnent plus, plutôt que d’explorer de nouvelles approches incertaines.
Nous savons désormais que Google utilise les données « d’interaction utilisateur » dans ses classements, comme l’indique ce document de Google issu du procès antitrust : « Ce dialogue est la source de la magie. »

Nous savons également, grâce aux fuites de l'API Google Data Warehouse, que Google collecte des données sur les « bons clics », les « mauvais clics », les « derniers clics les plus longs », etc.
Le Témoignage du ministère de la Justice a également révélé NavBoost et Glue, qui sont des signaux de classement de base liés au comportement des utilisateurs dans les résultats de recherche.
Nous savons également, grâce aux fuites, que Google semble utiliser les données de clics du navigateur Chrome dans le classement.
Emporter
Tous ces éléments mènent à la même conclusion : le comportement des utilisateurs est important. Beaucoup.
En tant que spécialistes du référencement, nous devons analyser le comportement des utilisateurs sur une page à l'aide d'outils tels que Hotjar et Lucky Orange. Ces outils nous aident à comprendre comment les utilisateurs interagissent avec la page.
Ces informations nous permettent de tester des idées pour améliorer l'expérience utilisateur et booster les classements. De plus, tester les taux de clics (CTR) est également crucial pour le référencement.
3. Apprentissage automatique
La meilleure façon d’expliquer cela est d’utiliser une étude Facebook de 2013.
« Une étude menée par l’Université de Cambridge en collaboration avec Microsoft a révélé qu’en utilisant les données « J’aime », qui sont disponibles publiquement par défaut, ils pouvaient faire des prédictions précises sur les attributs personnels – le plus surprenant étant un lien apparent entre le fait d’aimer les « Curly Fries » et le fait d’avoir un QI élevé. »
– «Aimer les frites frisées sur Facebook révèle votre QI élevé« WIRED
Comment cela peut-il avoir un sens ? Ce n’est pas le cas. C’est un schéma que la machine a identifié.
Pour une raison inconnue, les personnes ayant un QI plus élevé ont aimé les photos de « frites frisées » sur Facebook, et un algorithme d’apprentissage automatique a détecté ce modèle.
Dans la recherche, l’apprentissage automatique a sans aucun doute identifié certains modèles qui peuvent ne pas avoir de sens pour nous, mais qui en ont du point de vue d’une machine.
Par exemple, si une page contient des boutons bleus, les utilisateurs pourraient préférer la page. (Ceci est simplement un exemple pour expliquer l'idée ; il n'est pas basé sur des recherches réelles.)
Emporter
Nous ne pouvons pas faire grand-chose dans cette guerre « de l’homme contre la machine », mais cela vaut la peine d’analyser, de consulter des pages et d’essayer de trouver des modèles.
Même si je ne vois pas beaucoup de conseils pratiques pour nous ici en tant que référenceurs, je vois une explication à la raison pour laquelle certaines choses sont classées.
4. Intention de l'utilisateur
L’intention de l’utilisateur est sans doute le signal de classement le plus important, du moins lorsqu’il s’agit de signaux que nous pouvons contrôler.
J'ai récemment remarqué que Reddit et les blogs apparaissent souvent dans les SERP. Ils se classent pour ce que nous pensions être un mot-clé purement commercial/transactionnel.
Voici un exemple d'un Article du New York Times classé en 5ème position pour le mot clé « cartables » :
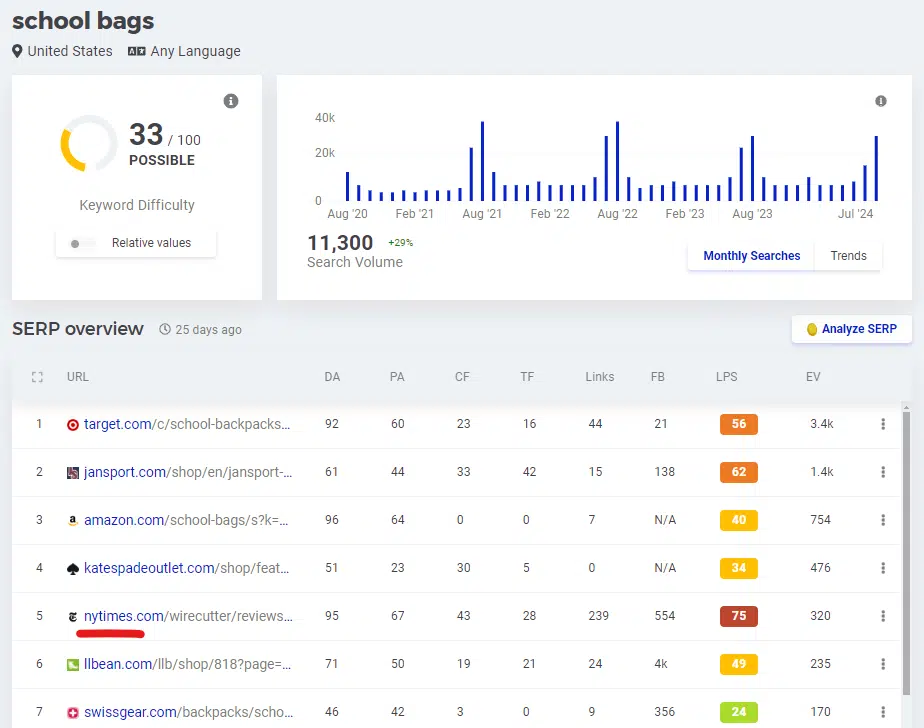
Emporter
Analysez l’intention de recherche et assurez-vous que vos pages couvrent différentes intentions.
S'il y a des blogs dans les SERP que vous ciblez, votre contenu doit inclure plus d'informations, même s'il s'agit d'une page de catégorie de produits.
Vous pouvez créer un blog de support sans craindre la cannibalisation, car c'est ce que recherchent les utilisateurs.
Si les résultats contiennent du contenu généré par les utilisateurs (UGC), vous souhaiterez peut-être inclure des avis sur vos pages ou activer les commentaires pour les blogs, par exemple. Il n'existe pas de méthode unique pour procéder.
Mon conseil ? Continuez à tester.
5. Bugs et tests
De nombreux facteurs entrent en jeu pour qu'un élément soit bien classé sur Google. Parfois, il s'agit simplement d'un bug de leur côté, et ils le corrigent.
Par exemple, Google a confirmé un bug de classement de recherche le 16 août, qui n’a pas été résolu avant le 20 août.
L’article de The Verge était bien classé au début, mais sa position a chuté après moins de deux mois.
Cela montre qu'un classement élevé ne signifie pas toujours qu'il est permanent ; Google teste probablement l'URL et collecte des données sur les utilisateurs.
Emporter
Il ne faut pas tirer de conclusions hâtives lorsque l’on constate des changements. Il faut être patient et observer avant de parvenir à un verdict ou d’établir une théorie de classement.
Décrypter les résultats de recherche inattendus de Google
Le référencement naturel (SEO) est bien plus complexe qu'il n'y paraît.
Aujourd’hui, le référencement représente bien plus que des mots-clés et des tactiques traditionnelles.
Nous devons être ouverts à des approches plus créatives.
Les temps ont changé en matière de recherche. Nous devons faire de même.
Entrons dans l’ère du « nouveau SEO ».
Les auteurs contributeurs sont invités à créer du contenu pour Search Engine Land et sont choisis pour leur expertise et leur contribution à la communauté de recherche. Nos contributeurs travaillent sous la supervision de la rédaction et leurs contributions sont vérifiées pour leur qualité et leur pertinence pour nos lecteurs. Les opinions qu'ils expriment sont les leurs.