
Comprendre la différence entre les robots de recherche et les grattoirs est crucial pour le référencement.
Les robots de site Web se répartissent en deux catégories:
- Bots de première partie, que vous utilisez pour auditer et optimiser votre propre site.
- Des robots tiers, qui rampent votre site à l'extérieur – parfois pour indexer votre contenu (comme Googlebot) et d'autres fois pour extraire des données (comme les gratteurs concurrents).
Ce guide décompose les robots de premier parti qui peuvent améliorer le référencement technique et les robots tiers de votre site, explorant leur impact et comment les gérer efficacement.
Crawlers de première partie: Mining Insights de votre propre site Web
Les Crawlers peuvent vous aider à identifier les moyens d'améliorer votre référencement technique.
L'amélioration des fondements techniques de votre site, de la profondeur architecturale et de l'efficacité de la cale est une stratégie à long terme pour augmenter le trafic de recherche.
Parfois, vous pouvez découvrir des problèmes majeurs – comme un fichier robots.txt bloquant tous les robots de recherche sur un site de mise en scène qui a été actif après le lancement.
La résolution de tels problèmes peut entraîner des améliorations immédiates de la visibilité de la recherche.
Maintenant, explorons certaines technologies basées sur la rampe que vous pouvez utiliser.
Googlebot via la console de recherche
Vous ne travaillez pas dans un centre de données Google, vous ne pouvez donc pas lancer Googlebot pour ramper votre propre site.
Cependant, en vérifiant votre site avec Google Search Console (GSC), vous pouvez accéder aux données et aux idées de Googlebot. (Suivre Guide de Google pour vous installer sur la plate-forme.)
GSC est libre à utiliser et fournit des informations précieuses – en particulier sur l'indexation des pages.
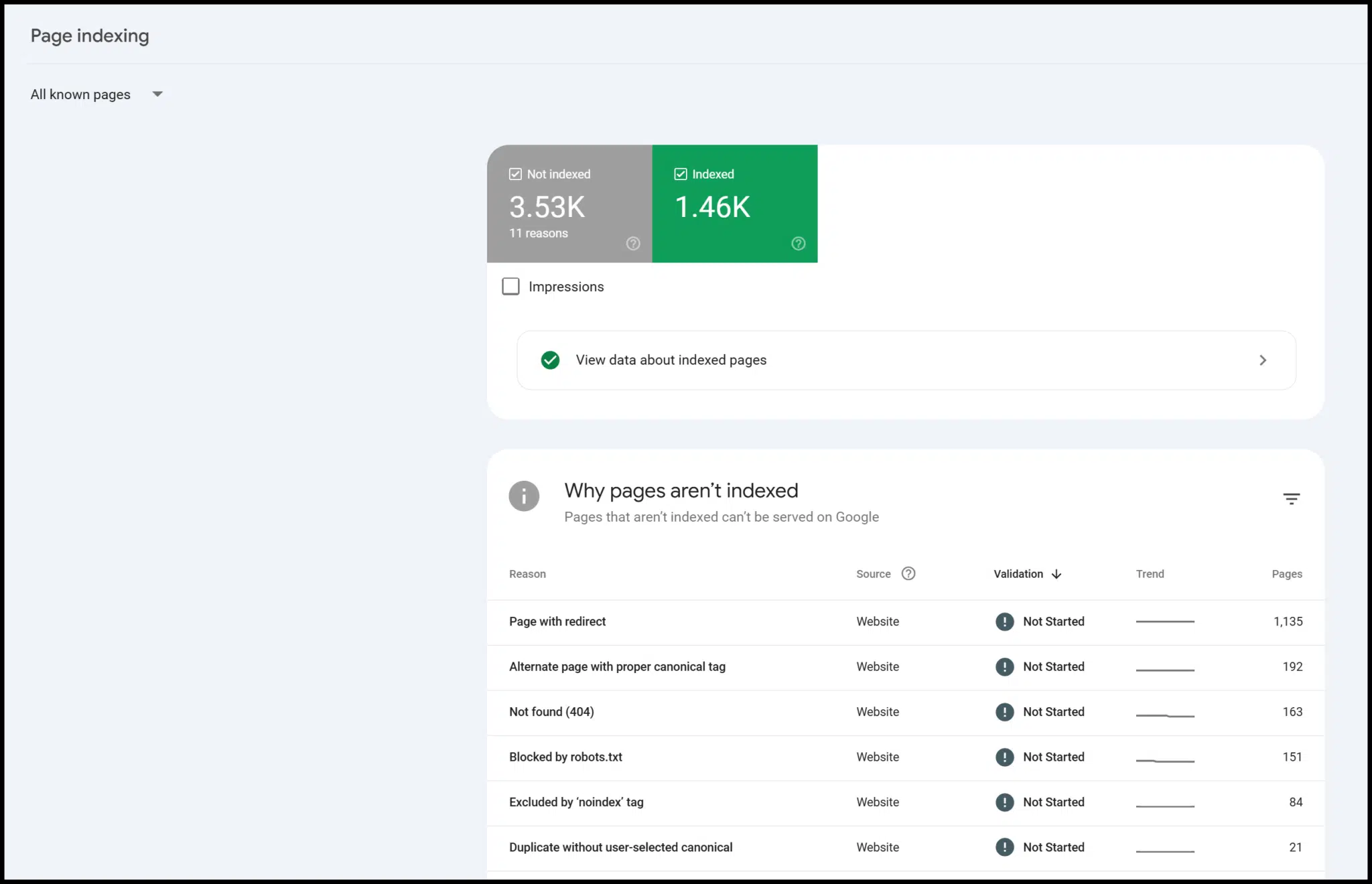
Il existe également des données sur la convivialité, les données structurées et les vitaux du Web de base:
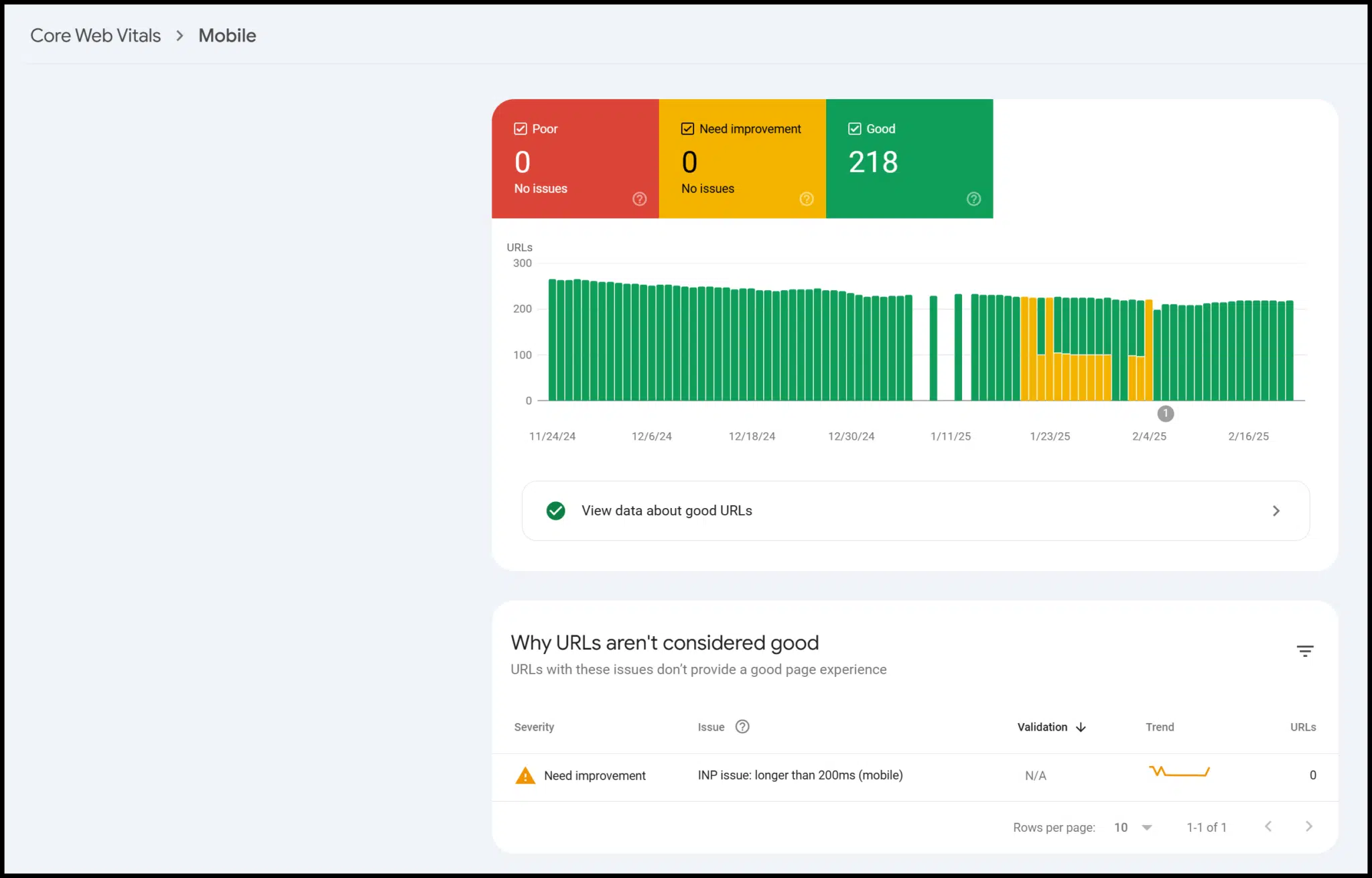
Techniquement, il s'agit de données tierces de Google, mais seuls les utilisateurs vérifiés peuvent y accéder pour leur site.
En pratique, il fonctionne un peu comme les données d'un rampe que vous exécutez vous-même.
Screaming Frog Seo Spider
Screaming Frog est une application de bureau qui s'exécute localement sur votre machine pour générer des données d'exploration pour votre site Web.
Ils proposent également un analyseur de fichiers journaux, ce qui est utile si vous avez accès aux fichiers journaux du serveur. Pour l'instant, nous nous concentrerons sur Screaming Frog's Spider de Frog.
À 259 $ par an, il est très rentable par rapport à d'autres outils qui facturent autant par mois.
Cependant, parce qu'il fonctionne localement, ramper s'arrête si vous éteignez votre ordinateur – il ne fonctionne pas dans le cloud.
Pourtant, les données qu'il fournit est rapide, précise et idéale pour ceux qui veulent plonger plus profondément dans le référencement technique.
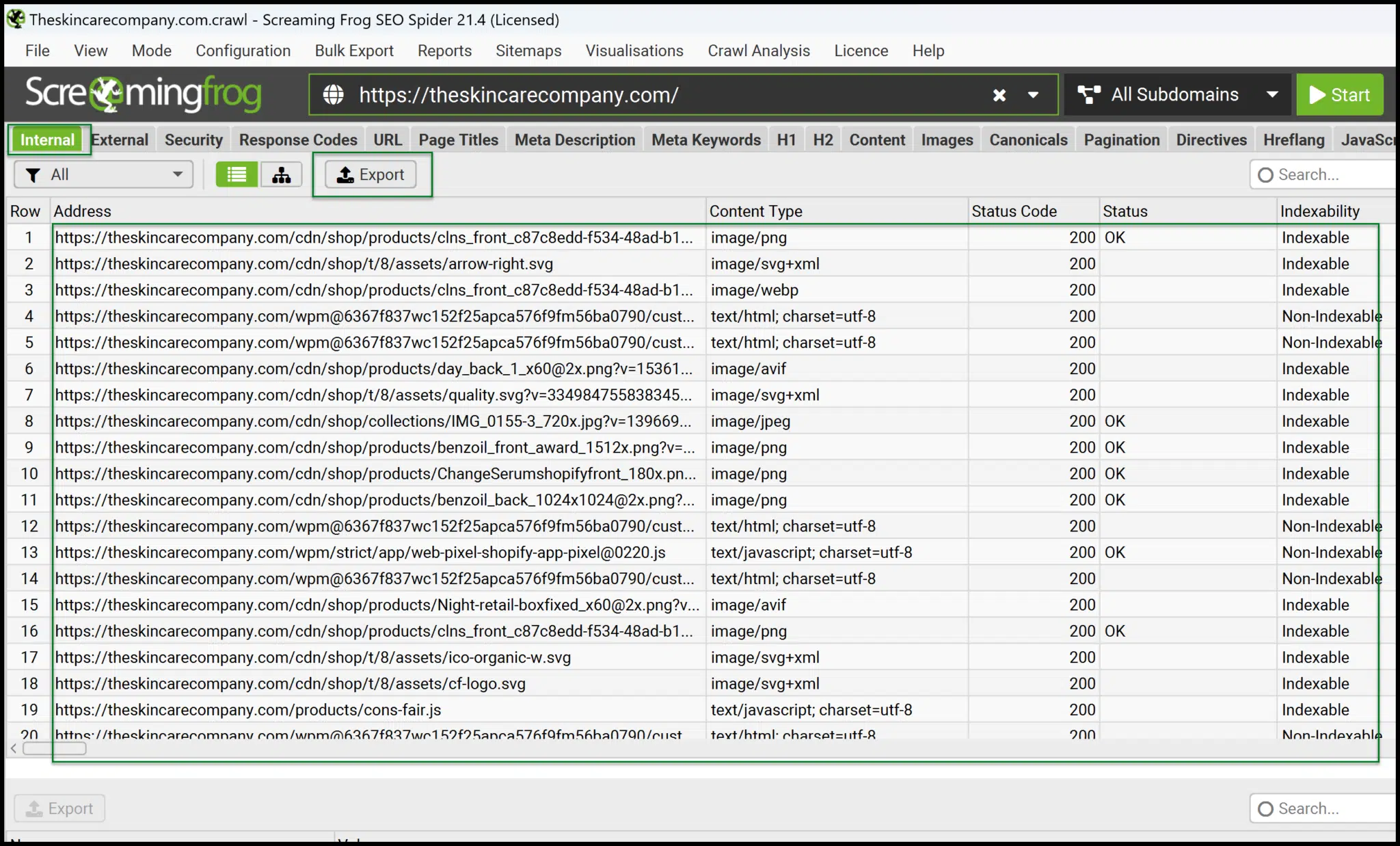
À partir de l'interface principale, vous pouvez rapidement lancer vos propres rampes.
Une fois terminé, exporter Interne> Toutes les données à un format excel-lisible et mettez à l'aise de manipuler et de pivoter les données pour des informations plus profondes.
Screaming Frog propose également de nombreuses autres options d'exportation utiles.
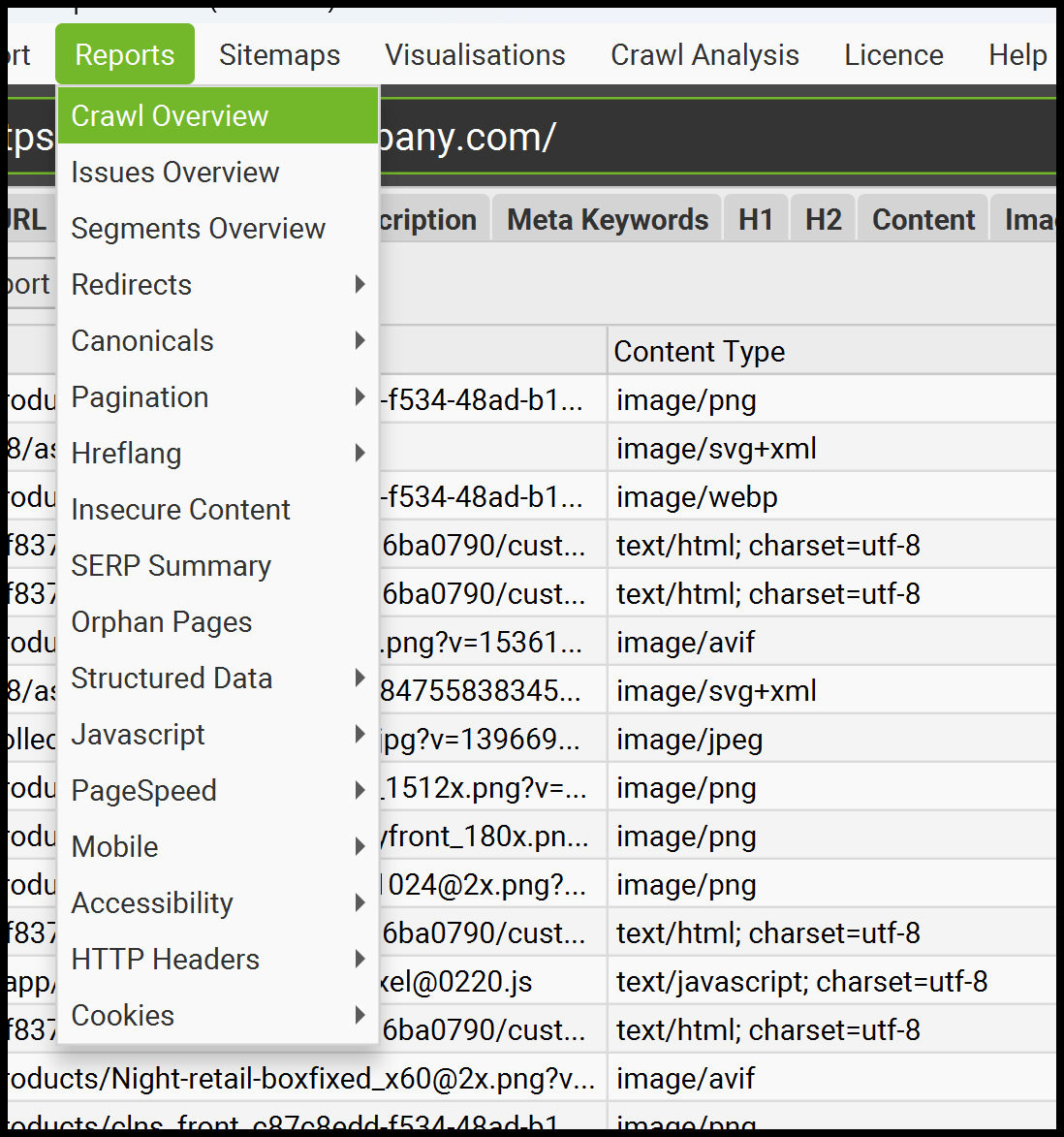
Il fournit des rapports et des exportations pour la liaison interne, les redirectes (y compris les chaînes de redirection), le contenu non sécurisé (contenu mixte), etc.
L'inconvénient est qu'il nécessite plus de gestion pratique, et vous devrez être à l'aise de travailler avec des données dans Excel ou Google Sheets pour maximiser sa valeur.
Audit du site Ahrefs
Ahrefs est une plate-forme complète basée sur le cloud qui comprend un robot de référencement technique dans son module d'audit de site.
Pour l'utiliser, configurez un projet, configurez les paramètres d'exploration et lancez la rampe pour générer des informations techniques de référencement.
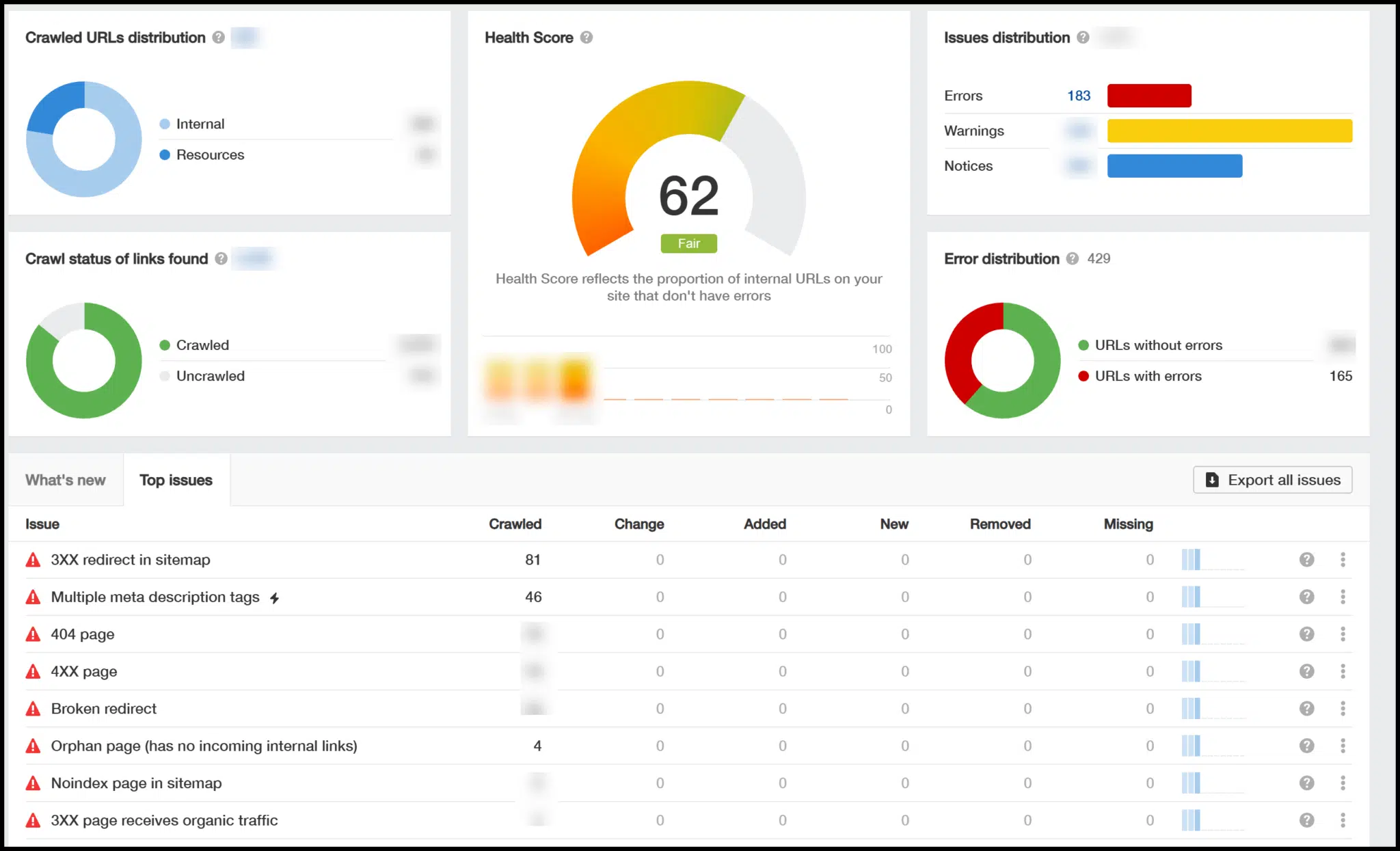
Une fois la rampe terminée, vous verrez un aperçu qui comprend une cote de santé technique de référencement (0-100) et met en évidence les problèmes clés.
Vous pouvez cliquer sur ces problèmes pour plus de détails, et un bouton utile apparaît lorsque vous plongez plus profondément, expliquant pourquoi certaines corrections sont nécessaires.
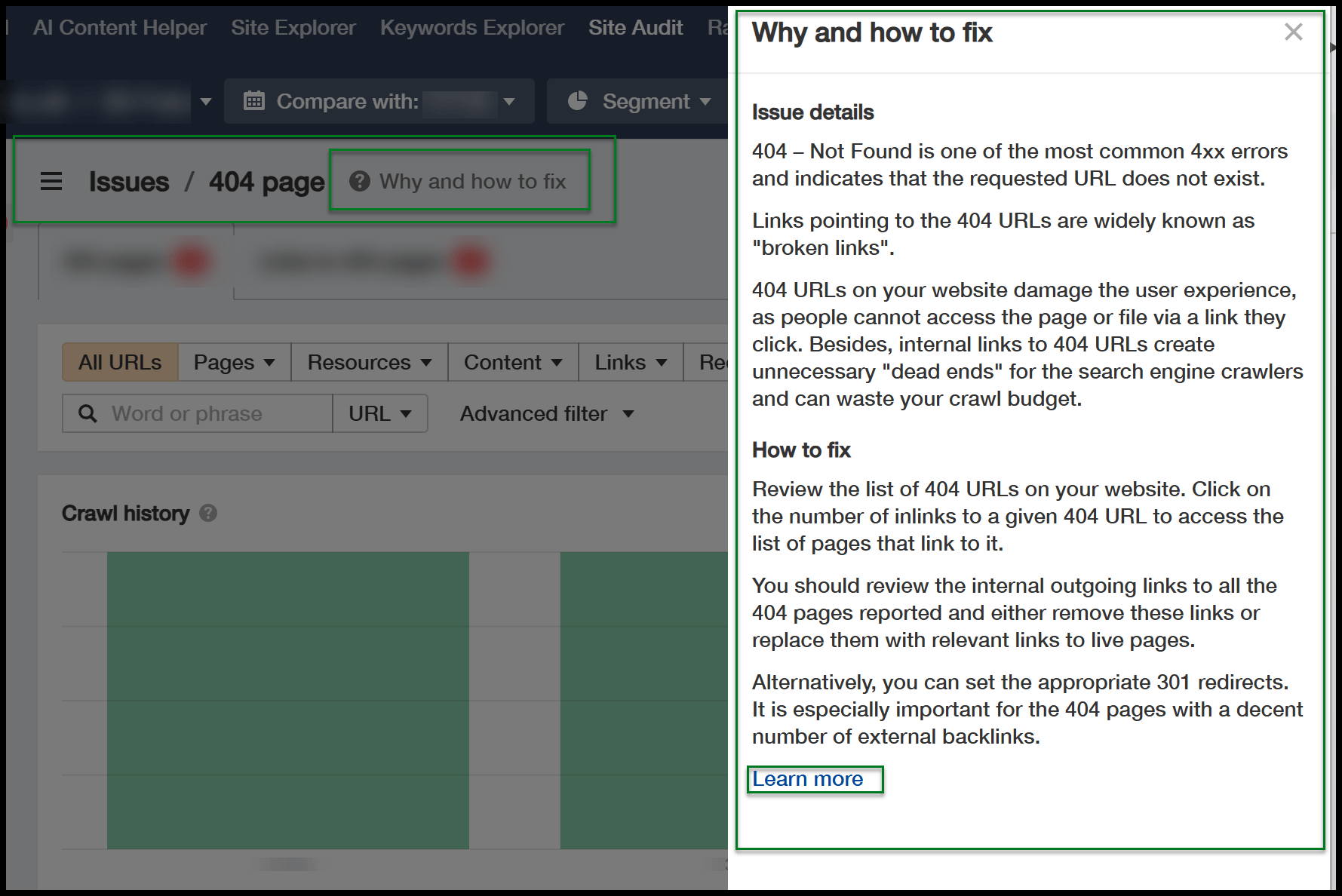
Étant donné qu'Ahrefs fonctionne dans le cloud, l'état de votre machine n'affecte pas la rampe. Il continue même si votre PC ou Mac est désactivé.
Par rapport à la grenouille hurlante, Ahrefs fournit plus de conseils, ce qui facilite la transformation des données en renseignements révolutionnables en informations réalisables.
Cependant, c'est moins rentable. Si vous n'avez pas besoin de ses fonctionnalités supplémentaires, comme les données de backlink et la recherche sur les mots clés, cela peut ne pas valoir les dépenses.
Audit du site Semrush
Ensuite, Semrush, une autre plate-forme puissante basée sur le cloud avec un robot de référencement technique intégré.
Comme Ahrefs, il fournit également des outils d'analyse de backlink et de recherche de mots clés.
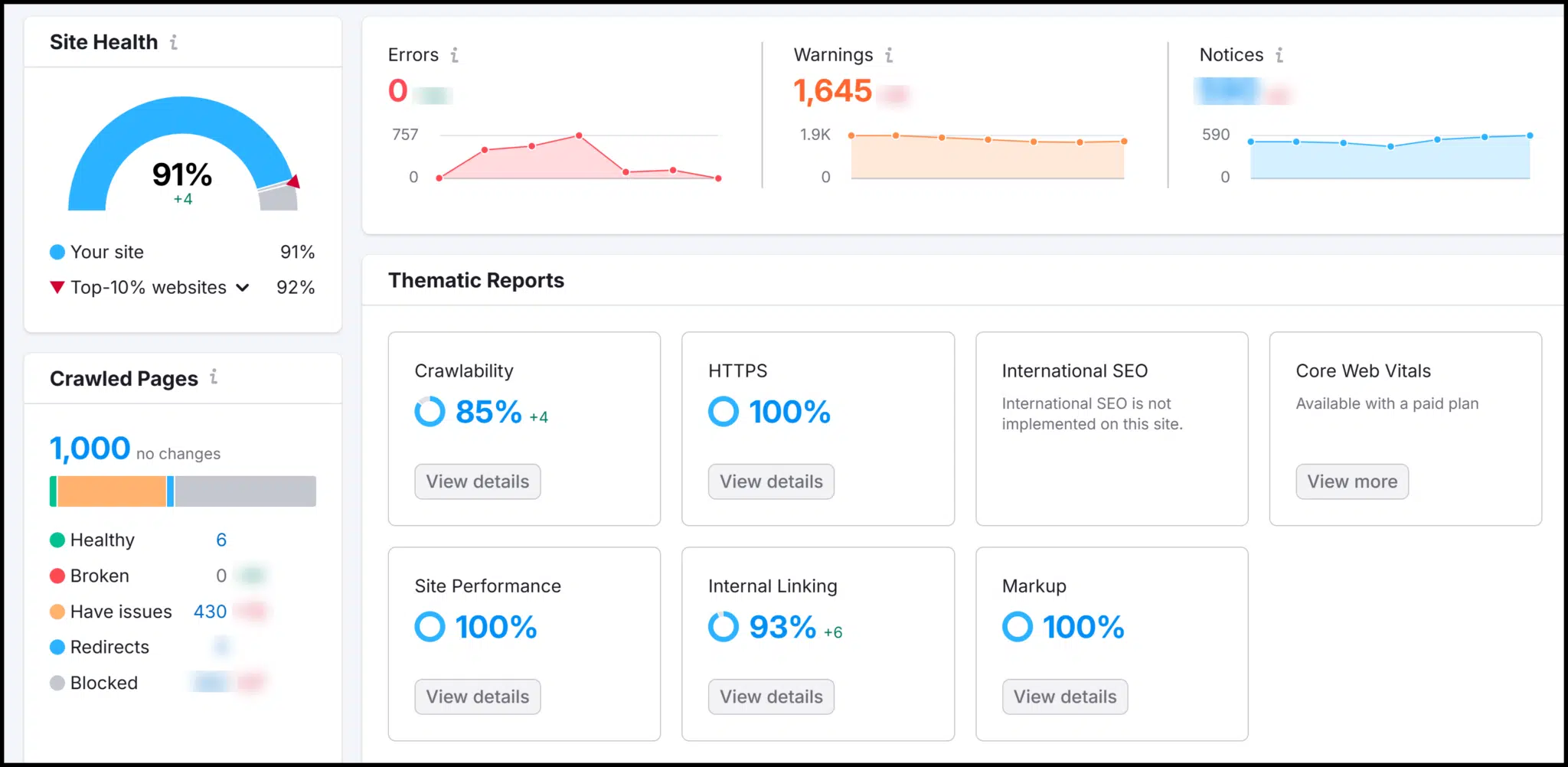
SemRush offre une cote technique de santé SEO, qui s'améliore lorsque vous résolvez les problèmes du site. Son aperçu de Crawl met en évidence les erreurs et les avertissements.
Pendant que vous explorez, vous trouverez des explications sur les raisons pour lesquelles des correctifs sont nécessaires et comment les implémenter.
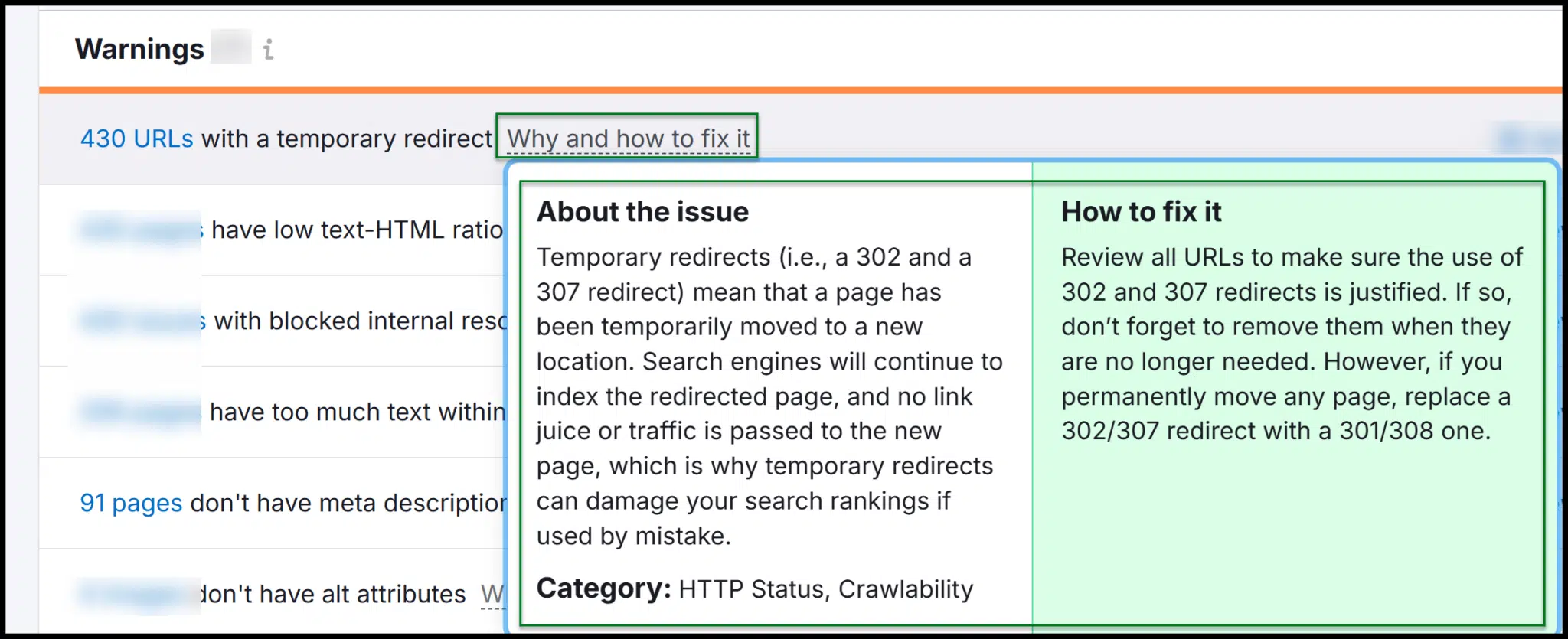
Semrush et Ahrefs ont des outils d'audit de sites robustes, ce qui facilite le lancement de Crawls, d'analyser les données et de fournir des recommandations aux développeurs.
Bien que les deux plates-formes soient plus chères que les grenouilles qui hurlent, elles excellent à transformer les données de rampe en informations exploitables.
Semrush est légèrement plus rentable qu'Ahrefs, ce qui en fait un choix solide pour ceux qui sont nouveaux dans le référencement technique.
Crawlers tiers: robots qui pourraient visiter votre site Web
Plus tôt, nous avons discuté de la façon dont des tiers pourraient ramper votre site Web pour diverses raisons.
Mais quels sont ces robots externes et comment pouvez-vous les identifier?
Comme mentionné, vous pouvez utiliser Google Search Console pour accéder à certaines des données d'exploration de Googlebot pour votre site.
Sans Googlebot rampant votre site, il n'y aurait pas de données à analyser.
(Vous pouvez en savoir plus sur les robots de rampe communs de Google dans ce Rechercher la documentation centrale.)
Les robots les plus courants de Google sont:
- Smartphone Googlebot.
- Googlebot Desktop.
Chacun utilise des moteurs de rendu séparés pour le mobile et le bureau, mais les deux contiennent «Googlebot/2.1«Dans leur chaîne d'agent utilisateur.
Si vous analysez vos journaux de serveurs, vous pouvez isoler le trafic Googlebot pour voir les zones de votre site, il rampe le plus fréquemment.
Cela peut aider à identifier les problèmes de référencement techniques, tels que les pages que Google ne rampent pas comme prévu.
Pour analyser les fichiers journaux, vous pouvez créer des feuilles de calcul pour traiter et pivoter les données à partir de fichiers .txt ou .csv bruts. Si cela semble complexe, l'analyseur de fichiers journaux de Frog Criry est un outil utile.
Dans la plupart des cas, vous ne devez pas bloquer Googlebot, car cela peut affecter négativement le référencement.
Cependant, si Googlebot est coincé dans une architecture de site très dynamique, vous devrez peut-être bloquer des URL spécifiques via Robots.txt. Utilisez-le attentivement – la surutilisation peut nuire à votre classement.
Faux trafic Googlebot
Tout le trafic ne prétendant pas être Googlebot n'est pas légitime.
De nombreux robots et grattoirs permettent aux utilisateurs de l'entraîner des chaînes d'agent utilisateur, ce qui signifie qu'ils peuvent se déguiser en Googlebot pour contourner les restrictions de chapelure.
Par exemple, la grenouille hurlante peut être configurée pour usurper l'identité de Googlebot.
Cependant, de nombreux sites Web – en particulier ceux hébergés sur de grands réseaux cloud comme AWS – peuvent faire la différence entre le trafic réel et le faux Googlebot.
Ils le font en vérifiant si la demande provient des gammes IP officielles de Google.
Si une demande prétend être Googlebot mais est originaire de ces gammes, elle est probablement fausse.
Autres moteurs de recherche
En plus de Googlebot, d'autres moteurs de recherche peuvent ramper votre site. Par exemple:
- Bingbot (Microsoft Bing).
- Duckduckbot (DuckDuckgo).
- Yandexbot (Yandex, un moteur de recherche russe, mais pas bien documenté).
- Baiduspider (Baidu, un moteur de recherche populaire en Chine).
Dans votre fichier robots.txt, vous pouvez créer des règles génériques pour interdire tous les robots de recherche ou spécifier des règles pour des robots et des répertoires particuliers.
Cependant, gardez à l'esprit que les entrées robots.txt sont des directives, pas des commandes – ce qui signifie qu'elles peuvent être ignorées.
Contrairement aux redirectes, qui empêchent un serveur de servir une ressource, Robots.txt est simplement un signal fort demandant aux robots de ne pas ramper certaines zones.
Certains robots peuvent ignorer complètement ces directives.
Hurler le robot d'exploration de grenouille
Screaming Frog s'identifie généralement avec un agent utilisateur comme Screaming Frog SEO Spider/21.4.
Le texte «Screaming Frog Seo Spider» est toujours inclus, suivi du numéro de version.
Cependant, Screaming Frog permet aux utilisateurs de personnaliser la chaîne d'agent utilisateur, ce qui signifie que les rampes peuvent apparaître à partir de Googlebot, Chrome ou d'un autre agent utilisateur.
Cela rend difficile de bloquer les rampes de grenouilles hurlantes.
Bien que vous puissiez bloquer les agents utilisateur contenant «Screaming Frog SEO Spider», un opérateur peut simplement modifier la chaîne.
Si vous soupçonnez une rampe non autorisée, vous devrez peut-être identifier et bloquer la gamme IP à la place.
Cela nécessite une intervention côté serveur de votre développeur Web, car Robots.txt ne peut pas bloquer les IPS – d'autant plus que la grenouille en criant peut être configurée pour ignorer les directives Robots.txt.
Soyez prudent, cependant. C'est peut-être votre propre équipe de référencement effectuant une analyse pour vérifier les problèmes techniques de référencement.
Avant de bloquer la grenouille hurlante, essayez de déterminer la source du trafic, car il pourrait s'agir d'un employé interne de collecte de données.
Ahrefs Bot
Ahrefs a un robot d'exploitation et un bot d'audit de site pour ramper.
- Lorsque Ahrefs rampe le Web pour son propre index, vous verrez le trafic de
AhrefsBot/7.0. - Lorsqu'un utilisateur Ahrefs exécute un audit de site, le trafic proviendra de
AhrefsSiteAudit/6.1.
Les deux bots respectent les robots.txt interdire les règles, selon la documentation d'Ahrefs.
Si vous ne voulez pas que votre site soit rampé, vous pouvez bloquer les ahrefs à l'aide de robots.txt.
Alternativement, votre développeur Web peut refuser les demandes d'agents utilisateur contenant «AhrefsBot » ou « AhrefsSiteAudit«.
Bot SEMRUSH
Comme Ahrefs, Semrush exploite plusieurs robots avec différentes chaînes d'agent utilisateur.
Assurez-vous de revoir toutes les informations disponibles pour les identifier correctement.
Les deux chaînes d'agent utilisateur les plus courantes que vous rencontrez sont:
- Semrushbot: Crawler Web général de Semrush, utilisé pour améliorer son index.
- Siteauditbot: Utilisé lorsqu'un utilisateur Semrush initie un audit de site.
Rogerbot, dotbot et autres robots
Moz, une autre plate-forme de référencement basée sur le cloud largement utilisée, déploie Rogerbot pour craquer des sites Web pour des informations techniques.
Moz exploite également Dotbot, un robot Web général. Les deux peuvent être bloqués via votre fichier robots.txt si nécessaire.
Un autre robot que vous pouvez rencontrer est MJ12BOT, utilisé par la plate-forme SEO majestueuse. En règle générale, ce n'est rien à craindre.
Bots de crawl non Seo
Tous les robots ne sont pas liés au référencement. De nombreuses plateformes sociales exploitent leurs propres robots.
Meta (la société mère de Facebook) exécute plusieurs robots, tandis que Twitter utilisait auparavant Twitterbot – et il est probable que X déploie désormais un système similaire, mais moins documenté.
Les Crawlers scannent en continu le Web pour les données. Certains peuvent bénéficier à votre site, tandis que d'autres doivent être surveillés via des journaux des serveurs.
Comprendre les robots de recherche, les robots de référencement et les grattoirs pour le référencement technique
Gérer les robots des robots premiers et tiers est essentiel pour maintenir le référencement technique de votre site Web.
Principaux à retenir
- Crawlers de première partie (Par exemple, Screaming Frog, Ahrefs, Semrush) Aidez à auditer et à optimiser votre propre site.
- Googlebot Insights via la console de recherche fournit des données cruciales sur l'indexation et les performances.
- Crawlers tiers (Par exemple, Bingbot, Ahrefsbot, Semrushbot) Craquez votre site pour une indexation de recherche ou une analyse compétitive.
- Gestion des robots via Robots.txt et les journaux de serveurs peuvent aider à contrôler les robots indésirables et à améliorer l'efficacité de la crawl dans des cas spécifiques.
- Compétences de traitement des données sont cruciaux pour extraire des informations significatives des rapports d'exploration et des fichiers journaux.
En équilibrant l'audit proactif avec la gestion stratégique des bots, vous pouvez vous assurer que votre site reste bien optimisé et rampé efficacement.
Les auteurs contributifs sont invités à créer du contenu pour les terrains de moteur de recherche et sont choisis pour leur expertise et leur contribution à la communauté de recherche. Nos contributeurs travaillent sous la surveillance du personnel éditorial et les contributions sont vérifiées pour la qualité et la pertinence pour nos lecteurs. Les opinions qu'ils expriment sont les leurs.